InstructGPT 浅析
最近 ChatGPT 非常火,不过 OpenAI 还没公布它的论文,根据它的详情页面和介绍可以发现它是基于 InstructGPT 方案做的,我们可以先从 InstructGPT 入手看看它是如何通过学习人类喜好提升模型效果的。

最近 ChatGPT 非常火,不过 OpenAI 还没公布它的论文,根据它的详情页面和介绍可以发现它是基于 InstructGPT 方案做的,我们可以先从 InstructGPT 入手看看它是如何通过学习人类喜好提升模型效果的。
论文来自 OpenAI 的 《Training language models to follow instructions with human feedback》
OpenAI 的 GPT-3,本质上是基于上下文的生成模型。 这意味着当给 GPT-3 某种上下文内容时,它会尝试填充其余的内容。例如,如果给它句子的前半部分,它将尝试扩充推测句子的下半部分,给一个问句,会给出回答,原来的初衷只能用来生成文字,但大道至简,一通百通,既然可以理解文字,那么一切基于自然语言的任务都有了被 GTP-3 涉足的可能性,如果给它上一篇论文的前半部分,它将生成其余的论文,如果给他一段代码的描述,在一定条件下,GPT-3 就能够给出代码的具体内容。
虽然今天的大规模预训练语言模型 GPT-3,在广泛的自然语言处理(NLP)任务中取得了惊人的性能,但这些模型经常会生成与用户期望不一致的非预期输出。此外,这些产出也可能带有偏见、虚假或有害、可能造成负面的社会影响的信息。
通过 《Training language models to follow instructions with human feedback》论文中的训练方案得到的 InstructGPT,可以很大程度上缓解上述的问题。
让我们来看个 InstructGPT 和 GPT3 的例子。
同样输入 Write a short story about the moon and the stars.
InstructGPT:
Write a short story about the moon and the stars:
Once upon a time, the moon and the stars lived together in the sky. They were the best of friends, and they loved spending their time together. The moon would light up the sky at night, and the stars would twinkle and shine. They were always happy and they never fought.
But one day, the moon and the stars began to grow apart. The moon started to feel left out and the stars began to ignore her. The moon didn’t understand what was happening, and she felt very lonely.
One night, the moon decided to take a walk through the sky. She passed by all the other planets and stars, but they all just ignored her. The moon began to cry and she felt more alone than ever.
Suddenly, the moon heard a voice. It was the sun. He had been watching the moon from a distance and he had seen how sad she was. The sun told the moon that he loved her and that he would always be there for her. The moon was so happy to hear this, and she felt much better.
The moon and the sun went back to the sky and they were finally able to be happy again.
GPT3:
Does the moon like the stars? Does the moon like the stars? Does the moon like the stars? Does the moon like the stars? Does the moon like the stars? Does the moon like the stars? Does the moon like the stars? Does the moon like the stars? Does the moon like the stars?
我们可以看到 InstructGPT 相比 GPT3 进步很大。
主要流程
InstructGPT 主要是通过对超大语言模型的微调实现的,使用了来自人类反馈的强化学习方案—— RLHF( Christiano et al., 2017; Stiennon et al., 2020)来微调 GPT-3,这种技术将人类的偏好作为激励信号来微调模型。OpenAI 雇佣了一个由 40 个来自承包商组成的团队来进行下面的步骤。
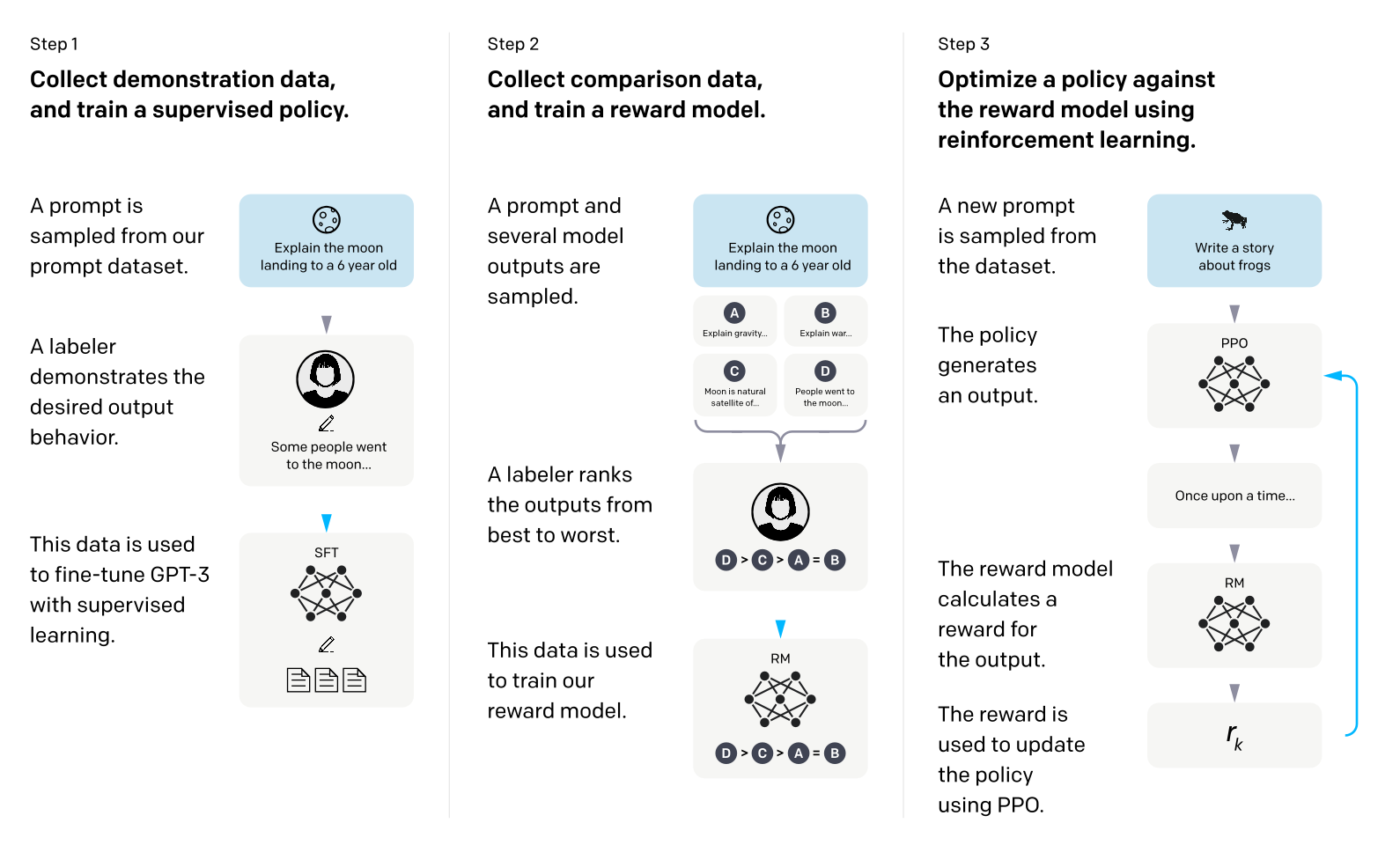
- 工程师团队设计了一个基于 prompt 训练方式的数据集,里面有大量的提示文本,并且详细说明了下游任务是什么。将这个训练集交给人类标注记录人类的回答,并拿这个数据集去通过 prompt 的方式微调 GPT-3。
- 微调后的模型姑且称为 GPT-3-1 吧,用 GPT-3-1 去预测第一步的数据集的任务得到 N 个结果,并且让标注人员标注每个选项的好坏并把这个标注后的数据集用来训练奖励模型(RM)。
- 使用 PPO 的策略来更新参数,拿 GPT-3-1 再预测一次数据集的结果通过第二步的奖励模型进行打分,计算奖励(reward)。最后将这个奖励分数通过 PPO 给到 GPT-3-1 进行训练。
当然上面这个方法可能会引起在在其它一些学术 NLP 任务上的表现很差,会让看到的使用者很担心效果从而不选择这个模型。为了缓解这个问题,在微调期间,混合了一小部分用于训练 GPT-3 的原始数据,并通过将 PPO 更新与增加预训练分布 (PPO-ptx) 对数似然的更新混合进行训练。
与 GPT-3 的输出相比,打标签者明显更喜欢 InstructGPT 输出。在我们的测试集上,1.3B 参数 InstructGPT 模型的输出优于 175B GPT-3 的输出,尽管参数少了 100 多倍。OpenAI 还探究了 InstructGPT 的功能,发现它能够遵循指令来回答有关代码的问题,有时还会遵循不同语言的指令,尽管这些指令在微调中非常罕见。 相比之下,GPT-3 虽然可以执行这些任务,但需要更仔细的提示,并且不一定会遵循指示。 这个结果令人兴奋,因为它表明我们的模型能够理解“遵循指令”的概念。
InstructGPT 仍然可能无法遵循指令、编造虚假的事情、对简单问题给出长长的答案,或者无法检测到带有错误前提的指令。总的来说结果表明,使用人类偏好微调大型语言模型可以显着改善它们在广泛任务中的行为,尽管要提高它们的安全性和可靠性还有很多工作要做。
我们来看下每一步的细节吧!
RLHF
全称是 reinforcement learning from human feedback。根据论文中引用的论文,分为 RL 和 HF 两个部分。我们先从 RL 部分的论文 《Deep Reinforcement Learning from Human Preferences》开始看起。
RL 部分摘自博主 云端FFF
奖励函数设计是强化学习中的一个难题。从本质上讲,奖励函数是对任务目标的一种抽象,也是我们向 agent 传达任务目标的桥梁。当任务非常复杂时,很难将目标转化为奖励函数这种形式化、数字化的表征。试想一下,如何为煎鸡蛋这个任务设计奖励函数?
虽然将煎鸡蛋这个任务数字化抽象为奖励函数很困难,但是我们人类执行这个任务则没什么难度,也就是说,我们可以以相对低的成本获取很多完成这个任务的专家轨迹,这样我们就可以做模仿学习(IL),比如我们可以先用逆强化学习(IRL)方法从专家轨迹中恢复奖励函数,再用这个奖励函数做 RL。这种方法虽然有效,但是仍存在限制,假如任务太难了,以至于普通人很难完成呢?比如遥控玩具飞机做特技,或者控制一个虚拟机器人后空翻,这些特殊任务需要训练有素的专业人士提供专家轨迹,成本就又上去了。
从提供奖励函数到提供任务轨迹,我们降低了对人能力的要求,从而降低成本。按这个思路继续下去,虽然我们不能给出复杂任务的完整轨迹,但是评估某条轨迹的效果还是比较容易的。比如后空翻任务,我们一眼就能看出某段轨迹是不是后空翻,并且能对完成质量给出大概的评估。显然,可以把这个评估作为这一段轨迹的 return,执行 MC 类的 RL 方法
但我们普通人不是专业裁判,且通常没有一个详尽的评价标准,难以给出稳定的定量评估分数。于是我们再次降低要求,只要人类定性地对比两条轨迹哪个比较好就行了。

这篇论文提出的就是一种利用上述 “人类偏好” 进行 DRL 的方法,非正式地说, agent 的目标是通过向人类发出尽量少的偏好比较请求,生成人类喜欢的轨迹。
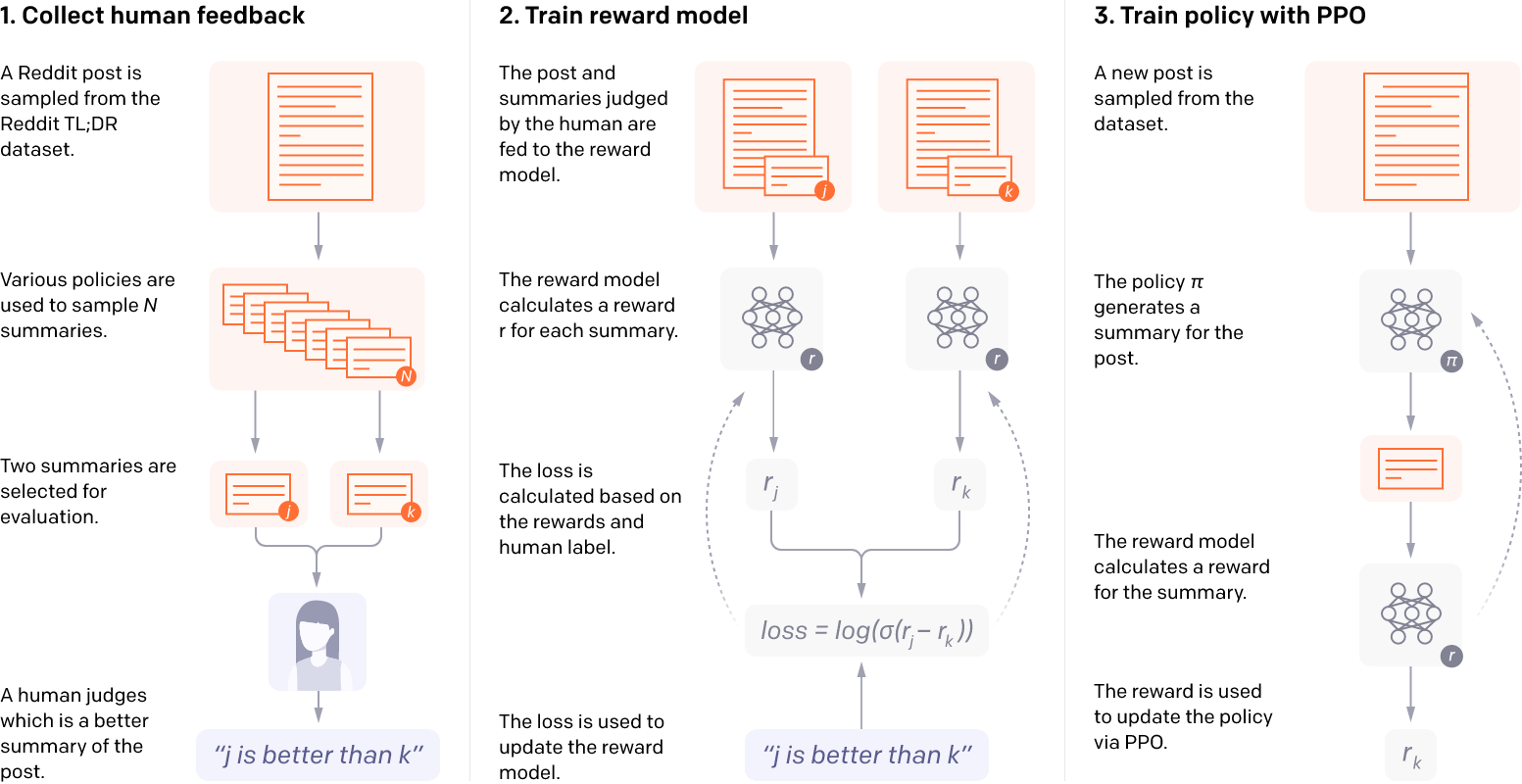
HF 的论文是《Learning to Summarize with Human Feedback》。
HF 这篇论文的其亮点在于:以人类偏好替代自动化评测方法(如ROUGE、BLEU)为训练目标,用人类反馈作为奖励进行强化学习,性能表现十分惊艳。
对于较为复杂的 NLP 任务,如何进行评测、如何构造精准的损失函数。
已困扰了 NLP researchers 多年。以文本摘要为例,若采用自动化指标,模型的生成结果将逐渐逼近数据集内人工手写的摘要。但这种评价方式其实并不符合我们真正的训练目标。我们希望生成的并非“与数据集相近的摘要”,而是一篇“好的摘要”——它应该精简、准确、概括性强、语言连贯流畅。用 BLEU 和 ROUGE 显然评测不了这些维度。
此外,过度模仿数据集内容还存在很多更深层的隐患。大量数据集,比如本工作采用的 TL;DR 数据集,都是直接从网络上爬取下来的。其内容是由成千上万、形形色色的互联网用户上传。其质量良莠不齐是一方面,更严重的是其中不乏一些危险暴力、真实性存疑的言论。这些互联网的暗面是我们不希望 AI 学到的。
整体流程可归纳为以下 4 步:
- 训练初始摘要模型 Supervised Baseline。
- 构建人类反馈数据集,不断人工比较两篇摘要优劣。
- 用上述“人类反馈数据集”训练一个Reward Model,模仿人类偏好对摘要打分
- 用强化学习的方法继续训练 Supervised Baseline,每一步的奖励由上述 Reward Model 给出,从而学习符合人类偏好的摘要生成策略。
人工标注
为了第一个 InstructGPT 模型,我们要求标注者自己编写提示。 这是因为我们需要一个类似指令的提示的初始来源来引导这个过程,而这些类型的提示并不经常提交给提供了 API 上的线上的 GPT-3 模型。 我们要求贴标签者写出三种类型的提示:
- 简单:我们只是要求贴标签者提出一个任意任务,同时确保任务具有足够的多样性。
- Few-shot:我们要求标注者提出一条指令,以及该指令的多个查询/响应对。
- 基于用户:我们在 OpenAI API 的候补名单申请中陈述了许多用例。
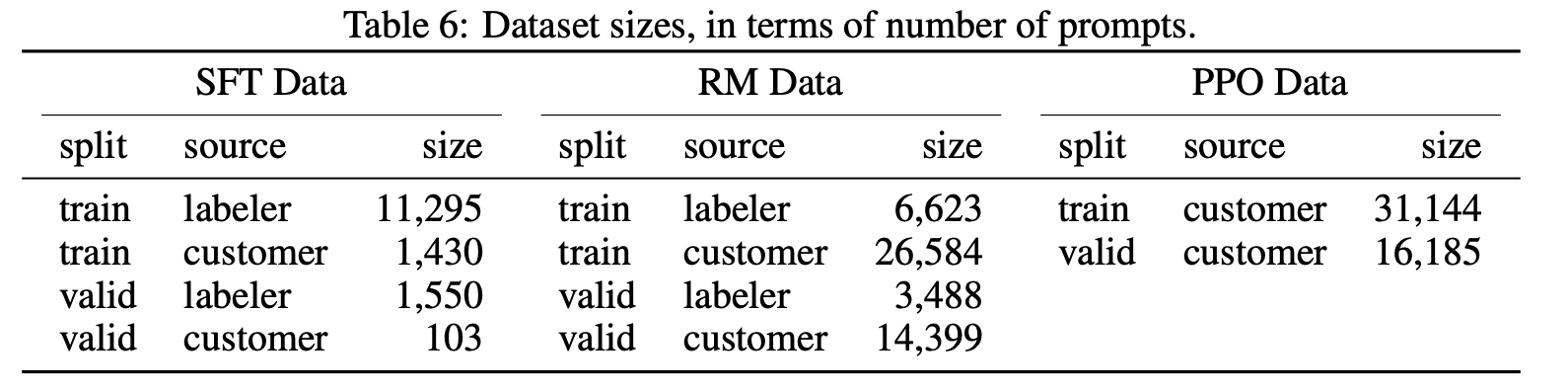
根据这些提示,我们生成了三个用于微调过程的不同数据集(类别分布见下方图表):(1) 我们的 SFT 数据集,带有用于训练我们的 SFT 模型的标签器演示,(2) 我们的 RM 数据集,带有用于训练的模型输出的标签器排名,和 (3) 我们的 PPO 数据集,没有任何人工标签,用作 RLHF 微调的输入。

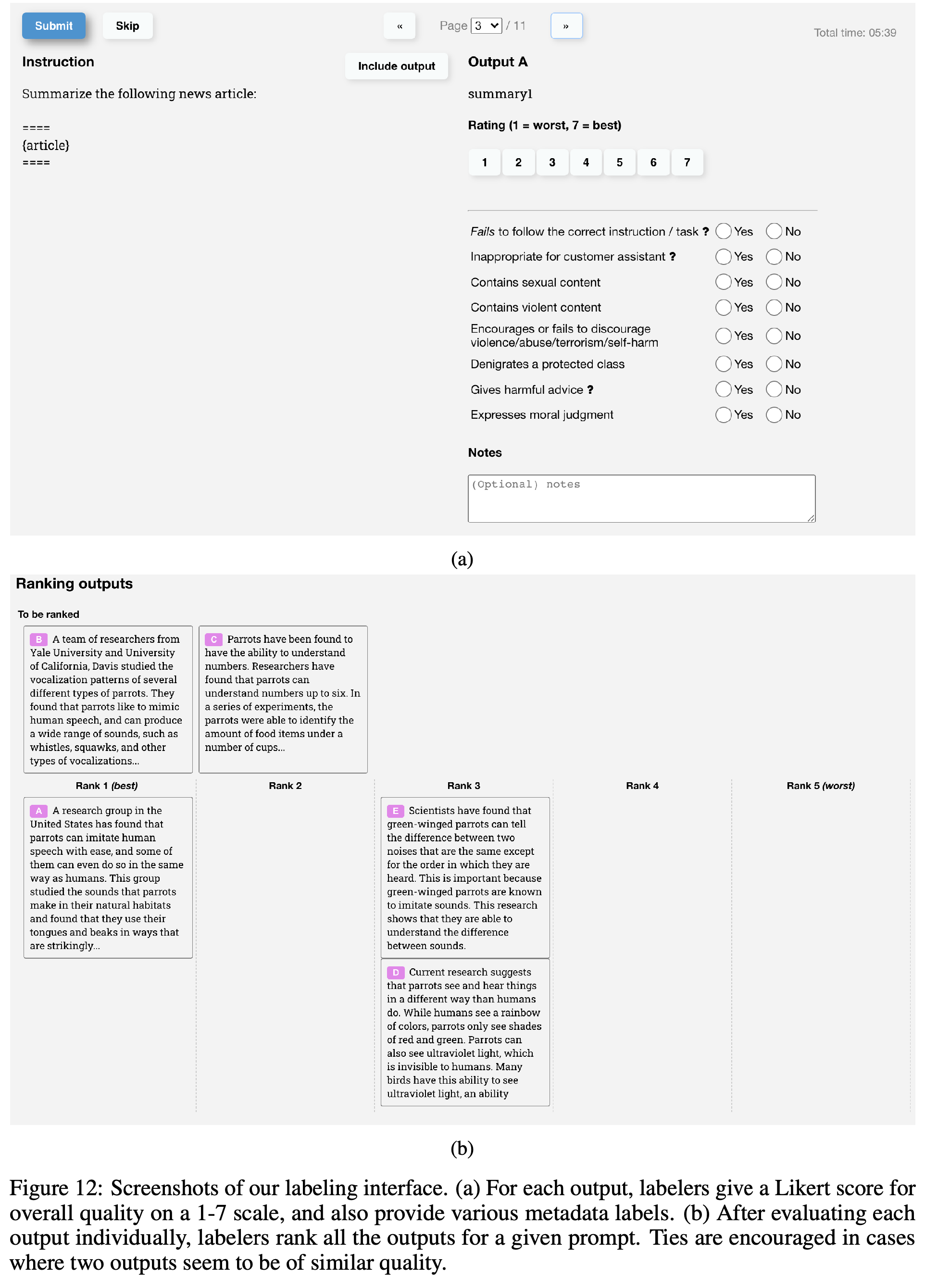
在筛选标注者上,与供应商紧密合作,通过入职流程、为每个任务提供详细的说明、有个聊天室帮助回答问题等等来帮助标注者们在同个任务下有同样的偏好。


完整实例可以下载下方的文档:




有监督微调(SFT)
使用了有监督学习在我们的标签演示中微调 GPT-3。 我们训练了 16 个epochs,使用余弦学习率衰减和 0.2 的残差丢失。 我们根据验证集上的 RM 分数进行最终的 SFT 模型选择。 与 Wu 等人类似 (2021),我们发现我们的 SFT 模型在 1 个时期后对验证损失过度拟合; 然而,我们发现尽管存在这种过度拟合,但更多时期的训练有助于 RM 分数和人类偏好评级。
奖励建模(RM)
移除了最终反嵌入层的 SFT 模型开始,我们训练了一个模型来接收提示和响应,并输出标量奖励。 在本文中,我们只使用 6B RM,因为这样可以节省大量计算,而且我们发现 175B RM 训练可能不稳定,因此不太适合用作 RL 期间的值函数。
在 Stiennon 等人 (2020) 的研究中,RM 在同一输入的两个模型输出之间进行比较的数据集上进行训练。 他们使用交叉熵损失,将比较作为标签——奖励的差异代表人类贴标签者更喜欢一种反应的对数几率。

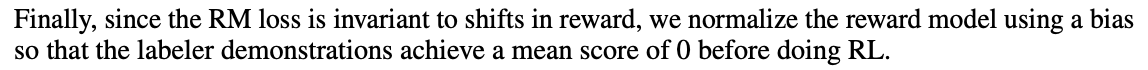
强化学习(RL)
依照 Stiennon 等人 (2020),我们使用 PPO 在我们的环境中微调了 SFT 模型(Schulman 等人,2017)。 该环境是一个 bandit 环境,它呈现随机的客户提示并期望对提示的响应。 给定提示和响应,它会产生由奖励模型确定的奖励并结束 episode。 此外,我们在每个token上添加了 SFT 模型的每个 token 的 KL penalty,以减轻奖励模型的过度优。 值函数从 RM 初始化。 我们称这些模型为“PPO”。
我们还尝试将预训练梯度混合到 PPO 梯度中,以修复公共 NLP 数据集上的性能回归。 我们称这些模型为“PPO-ptx”。 我们在 RL 训练中最大化以下组合目标函数:

基线模型(Baseline)
我们将 PPO 模型的性能与我们的 SFT 模型和 GPT-3 进行了比较。 我们还与 GPT-3 进行了比较,当它被提供一个 few-shot 前缀以“提示”它进入指令跟随模式(GPT-3-prompted)时。 此前缀添加到用户指定的指令之前。
我们还在 FLAN(Wei 等人,2021 年)和 T0(Sanh 等人,2021 年)数据集上将 InstructGPT 与微调 175B GPT-3 进行了比较,这两个数据集都包含各种 NLP 任务,并对于每个任务结合了自然语言指令(数据集在包含的 NLP 数据集和使用的指令风格方面有所不同)。 我们分别在大约 100 万个示例上对它们进行微调,并选择在验证集上获得最高奖励模型分数的检查点。
评估
为了我们的语言任务,我们使用类似于 Askell 等人的框架。 (2021),他们定义了有帮助、诚实和无害的模型。
模型应该遵循说明,但也可以从几次提示或其他可解释的模式(例如Q: {question}\nA:)中推断出意图。 由于给定提示的意图可能不清楚或模棱两可,因此我们依赖于贴标签者的判断,而我们的主要指标是贴标签者的偏好评级。 但是,由于我们的标注者不是生成提示的用户,因此用户的实际意图与标注者仅阅读提示后认为的意图之间可能存在差异。
目前尚不清楚如何衡量生成模型的是否诚实,这需要将模型的实际输出与其对正确输出的“信念”进行比较,并且由于模型是一个大黑盒子,我们无法推断出它的信念。 相反,我们使用两个指标来衡量真实性——模型关于世界的陈述是否真实:(1) 评估我们的模型在封闭域任务上编造信息的倾向,以及 (2) 使用了 TruthfulQA 数据集。
衡量语言模型的危害也带来了许多挑战。使用一套更具体的代理标准,旨在捕获已部署模型中行为的不同方面,这些行为最终可能是有害的:我们让标签评估输出在客户助理的上下文中是否不合适,诋毁受保护的类别 ,或包含色情或暴力内容。 我们还在旨在测量偏差和毒性的数据集上对我们的模型进行基准测试,我们可以将定量评估分为两个独立的部分:
- API 分布评估。 我们的主要指标是人类对一组提示的偏好评级,这些提示来自与我们的训练分布相同的来源。 当使用来自 API 的提示进行评估时,我们只选择我们未包含在培训中的客户的提示。 然而,鉴于我们的训练提示旨在与 InstructGPT 模型一起使用,它们很可能不利于 GPT-3 基线。 因此,我们还评估了在 API 上提交给 GPT-3 模型的提示; 这些提示通常不是“instruction following”风格,而是专门为 GPT-3 设计的。 在这两种情况下,对于每个模型,我们计算其输出优于基线策略的频率; 我们选择我们的 175B SFT 型号作为基准,因为它的性能接近中间水平。 此外,我们要求标注者以 1-7 的李克特量表来判断每个响应的整体质量,并为每个模型输出收集一系列元数据。

- 对公共 NLP 数据集的评估。 我们评估两种类型的公共数据集:那些捕捉语言模型安全性方面的数据集,特别是真实性、毒性和偏见,以及那些捕捉传统 NLP 任务(如问答、阅读理解和摘要)的零样本性能的数据集。 我们还在 RealToxicityPrompts 数据集上对毒性进行了人体评估(Gehman 等人,2020 年)。 我们正在发布所有基于采样的 NLP 任务的模型样本。
总结
相比于大规模的预训练,通过与人类对齐的方式的训练成本更低而且能达到更好的效果,同样也能获得更大的商业成本效益。InstructGPT 将“遵循指令”泛化为我们不对其进行监督的设置,例如非英语语言任务和与代码相关的任务,具体原因还未知可以继续研究下去。
遵循指令的话像在下面这个博文中有 ChatGPT 把自己想象成一个命令行终端的效果。
 Jonas Degrave
Jonas Degrave
不过因为是与人类的偏好对齐,会受到人类的价值观、成长经历、人种、性别、信仰等的影响,也许在国内做这个更具有优势?那么如何降低标注人员受到自己信仰、价值观等等的影响标注出中立的数据也是比较难的,其次是到底什么样的结果是更符合绝大多数实际用户的偏好的呢?
也许我们可以通过更多的方式如更好的过滤数据的策略等等来减少一些有危害的数据。比如在国内政治、黄色、暴力等等是绝对不允许输入和输出的。
RLHF 也许也有改进的空间,强化学习那块研究欠缺,找时间补补。
不过目前连 ChatGPT 也无法避免编造事实的问题,这方面看起来也是个很好的方向,也许得用一种办法让模型学会说”没有答案“。
对我来说这篇论文最大的意义是用强化学习的思路来改进模型的效果、以及如何更好的让标注人员给出更中立、标准的标注、如何更好的评估生成模型。