
众所周知,文本是时序型数据,词与词之间的顺序关系往往影响整个句子的含义。
有个男生是小帅哥 -> 有个小帅哥是男生 -> 小男生有个是帅哥
上面这三个句子虽然字上面没有不同,但是因为位置顺序变了语义就完全不一样了。所以我们在对文本数据进行建模的时候需要考虑词与词之间的顺序关系。
不同于 RNN(循环神经网络) 和 CNN(卷积神经网络)等模型,对于 Transformer 类的模型来说,因为纯粹的 Attention 模块是无法捕捉输入顺序的,即无法区分不同位置的 Token,所以位置编码是必要的。
在传统的 RNN 模型中,输入序列(比如一个句子)里的各个 token(比如词)按它们在序列中的前后位置被一个一个地处理,每个时间步 RNN 处理一个 token。虽然 tokens 本身的表达向量(比如词嵌入向量)并不携带任何位置信息,但因为一个时间步的输入要和上个时间的状态向量经过各自的线性变换后乘上两个矩阵再一起被 RNN 进行处理。由于每个时间步的状态向量是不同的,所以即使在不同的时间步出现相同的词,RNN 仍会区分开前后出现的词,从而产生不同的输出。我们可以认为,状态向量隐含了输入序列中的位置信息。其实它包含了过去时间步输入的词之间的语法和语义信息,这个信息对后续输入的词和输出产生的作用可以与位置信息的作用等同起来。
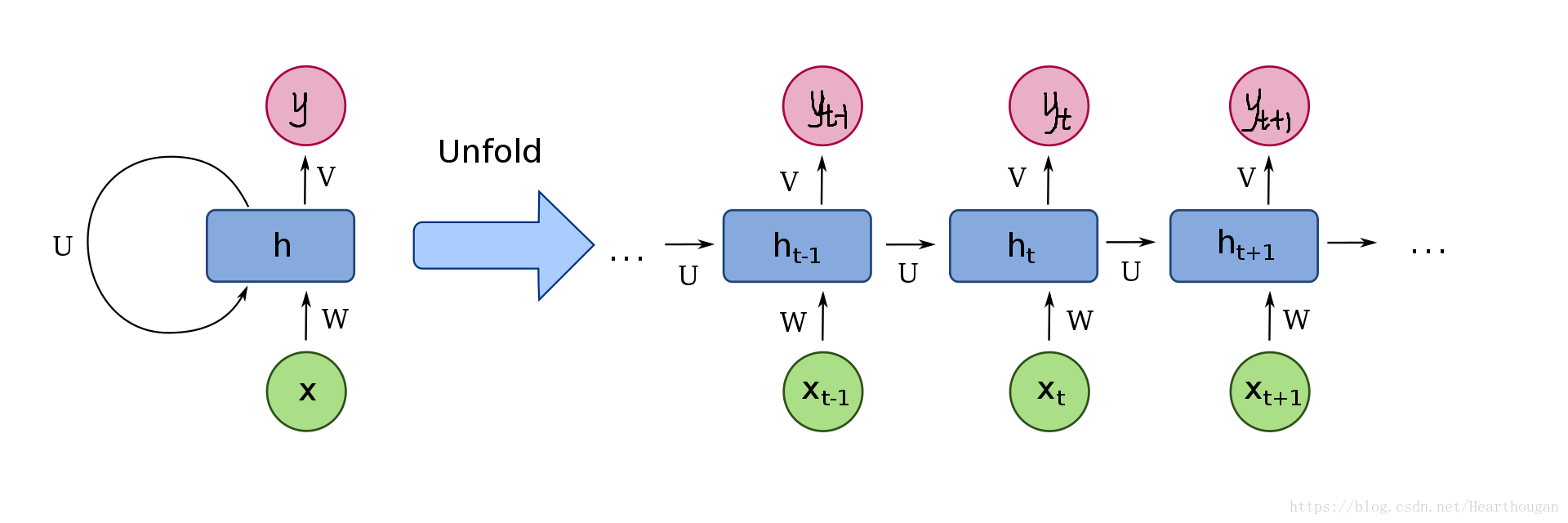
但是当一个序列输入进一个 Self-Attention 模块时,由于序列中所有的 tokens 是同时进入并被处理的,如果不提供位置信息,那么这个序列里的相同的 token 对 Self-Attention 模块来说就不会有语法和语义上的差别,它们会产生相同的输出。如果不在它们的向量中加入位置信息,那么 Self-Attention 模块产生的对它们的关注度是一样的,或者模型产生的新的表达(也就是嵌入向量)是一样的,诸如此类。所以,我们需要在输入序列里人为地加入每个 token 的位置信息。这个位置信息相当于起RNN 中的时间步的作用。
RNN(循环神经网络) 和 CNN(卷积神经网络) 基本属于位置敏感(输出会随着输入文本数据顺序的变化而变化)的神经网络结构,而 Transformer 恰好属于对位置不敏感的结构,所以我们需要额外给 Transformer 带上每一个字所在的位置。
我们一般可以通过两种办法:
- 想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;
- 想办法微调一下 Attention 结构,使得它有能力分辨不同位置的 Token,这构成了相对位置编码的一般做法。
绝对位置编码
现在普遍使用的一种方法 Learned Positional Embedding 编码绝对位置,相对简单也很容易理解。直接对不同的位置随机初始化一个 postion embedding,加到 word embedding 上输入模型,作为参数进行训练。
早在 17 年 Facebook 提出的《Convolutional Sequence to Sequence Learning》 提出了文本的最大长度为 512,而编码长度为 768,就需要初始化一个 512 * 768 的矩阵作为位置向量。
但绝对位置编码有个问题是,加入你的模型长度为 512,那么超过 512 的就无法处理了。也就无法训练更长长度的模型。
相对位置编码
使用绝对位置编码,不同位置对应的 positional embedding 固然不同,但是位置 1 和位置 2 的距离比位置 3 和位置 10 的距离更近,位置 1 和位置 2 与位置 3 和位置 4 都只相差 1,这些关于位置的相对含义模型能够通过绝对位置编码学习到吗?很显然在绝对位置下没法学会的,因为它们的绝对位置比较远。
相对位置并没有完整建模每个输入的位置信息,而是在算 Attention 的时候考虑当前位置与被 Attention 的位置的相对距离。
比如在 《Self-Attention with Relative Position Representations》提出了一种方案。比如下面这句话:
有个男生是帅哥
我们给它先按顺序打上绝对位置编码,[有, 个, 男, 生, 小, 帅, 哥] 得到 [0, 1, 2, 3, 4, 5, 6]。我们假设以“生”字为中心再给其它文字加个离“生”字有多远,得到 [-3, -2, -1, 0, +1, +2, +3],如上所例我们最终会得到下面这样的矩阵。
| 0 | 1 | 2 | 3 | 4 | 5 |
| -1 | 0 | 1 | 2 | 3 | 4 |
| -2 | -1 | 0 | 1 | 2 | 3 |
| -3 | -2 | -1 | 0 | 1 | 2 |
| -4 | -3 | -2 | -1 | 0 | 1 |
| -5 | -4 | -3 | -2 | -1 | 0 |
论文中提出了裁剪的方案,假设裁剪 k 为 2,那么所有大于 2 的自动变成。
| 0 | 1 | 2 | 2 | 2 | 2 |
| -1 | 0 | 1 | 2 | 2 | 2 |
| -2 | -1 | 0 | 1 | 2 | 2 |
| -2 | -2 | -1 | 0 | 1 | 2 |
| -2 | -2 | -2 | -1 | 0 | 1 |
| -2 | -2 | -2 | -2 | -1 | 0 |
为了方便后面作为索引,所有值加上 k 变成非负数。
| 2 | 3 | 4 | 4 | 4 | 4 |
| 1 | 2 | 3 | 4 | 4 | 4 |
| 0 | 1 | 2 | 3 | 4 | 4 |
| 0 | 0 | 1 | 2 | 3 | 4 |
| 0 | 0 | 0 | 1 | 2 | 3 |
| 0 | 0 | 0 | 0 | 1 | 2 |
这样就得到了一个新的 6*6 个相对位置编码,不过似乎在 k 小的时候可能会带走长期依赖关系,不过总归是是有益的吧,貌似可以聚合远处的信息,而且可以表达出任意长度的位置信息。



