
背景
对于部分信息获取的需求,在搜索场景下,直接返回答案会比返回相关文档再让用户去文档里找更直接和高效;另外,对于屏幕限制的设备,如手机和语音助手,直接返回简短答案的方式需求会更大。
按照问答系统解决问题的思路,常见的做法可以分为三类:
- FAQ:用问题在 QA(问答库)中搜索相似的问题,找到答案。
- KBQA:用问题在 结构化的知识库中搜索答案。
- ODQA:Open-Domain Question Answering(ODQA)任务最早在[1]中提出。具体来说,该任务给定一个文档集和一系列问题,模型需要在文档集中检索需要的内容,并根据检索的内容来回答这一系列问题。易见,该类任务在现实生活中有着非常重要而广泛的应用。
FAQ 是目前最成熟,工业界应用最广泛的问答系统技术方案。据笔者了解,阿里小蜜和微软小冰这种方案在日常应用场景的覆盖占比高达 70~80%。FAQ 好处是简单易干预,只要对误判别的问题添加相应的答案合并进 QA 库中,效果立竿见影。尤其是在垂类咨询场景中,80% 的用户问的都是 20% 的问题,对高频问题配置标准答案,然后转化为 QQ 匹配的方式,在项目早期迭代过程中性价比很不错。
但是 FAQ 到项目后期,可能 QA 库数量巨大,资源浪费比较严重,而且 QA 库实际有很多冗余,如咨询一个套餐的办理方式有很多种问法,如果新加了一个套餐,运营人员可能就得给问答库配置很多条对应的问题,不便于信息管理。这迫使人们将相关信息提取到更抽象级别的层次进行存储和管理,这就是基于知识库的问答。
知识库对计算机来说更易于读取和处理,但是存在不完备、模式固定等缺陷,在实际场景中,如果没有现成的结构化数据,还面临构建知识库成本昂贵,以及原始数据到知识库表示中间的信息折损问题。垂直封闭领域模式相对有限,可以通过完善知识库和知识建模形式进行弥补。而对于开放域,基本不太现实,这种情况下,又促使研究者回到使用原始文本回答问题上来。
FAQ
FAQ 其实是这个方向中最简单的,也是最朴素的一种做法。
基于 FAQ 的智能问答本质是一个信息检索的问题,所以可以简单划分成:召回 + 精排 两个步骤。召回的目标是从知识库中快速的召回一小批与 query 相关的候选集。所以召回模型的评价方法,主要侧重于 响应时间 和 top@n 的召回率 两个方面。
比如 ElasticSearch 中可以将问题分词后进行查找,利用 BM25 算法进行召回。
BM25 是信息索引领域用来计算 query 与文档相似度得分的经典算法。BM25 的设计依据一个重要的发现:词频和相关性之间的关系是非线性的,也就是说,每个词对于文档的相关性分数不会超过一个特定的阈值,当词出现的次数达到一个阈值后,其影响就不在线性增加了,而这个阈值会跟文档本身有关。
不同于TF-IDF,BM25的公式主要由三个部分组成:
- query 中每个单词 \(q\) 与文档 \(d\) 之间的相关性。
- 单词 \(q_i\) 与 query 之间的相似性
- 每个单词的权重。
$$\operatorname{Score}(Q, d)=\sum_{i}^{n} W_{i} R\left(q_{i}, d\right)$$
其中 \(Q\) 表示一条 query。\(W_i\) 是单词全中,也就是 IDF 值,R 是相关性得分。具体可以搜索下这个算法。
ElasticSearch 中拿到召回后可以找到第一个最相关的问题的答案即可。当然你也可以利用 Word2Vec 或者 Transformer 类模型 encoding 成向量然后再做向量之间的 cosine、l2 的距离对比即可。
追根究底就是找出最相似的问题后,根据这个已经在问答库有答案的问题找到相关的答案。
KBQA
知识库与数据库不同,是结构化的三元组(比如知识图谱)。而数据库,形式就非常多了,例如MySQL 数据库(结构化的)、Wikipedia数据库(纯文本)等。
KBQA其实非常好理解,就是给定一个知识库,模型使用这个知识库(知识图谱)进行训练,然后利用训练完后获得的知识回答问题。
知识库是一个结构化的数据库,它与知识图谱类似,由(主体 Subject,关系 Relation,客体 Object)三元组组成,例如(JK 罗琳,出生地,英国),常见的知识库有 Freebase 等。这个三元组可以用来回答 “JK 罗琳出生在哪里?” 的问题。与简单的、答案与主体直接相连的简单 QA 不同,复杂 QA 查询任务涉及多跳推理甚至一些聚合关系。例如下图知识库,“谁是 The Jeff Probst Show 提名的 TV Producer 的第一任妻子” 问题的答案,包含多个实体和多跳处理逻辑。[2]
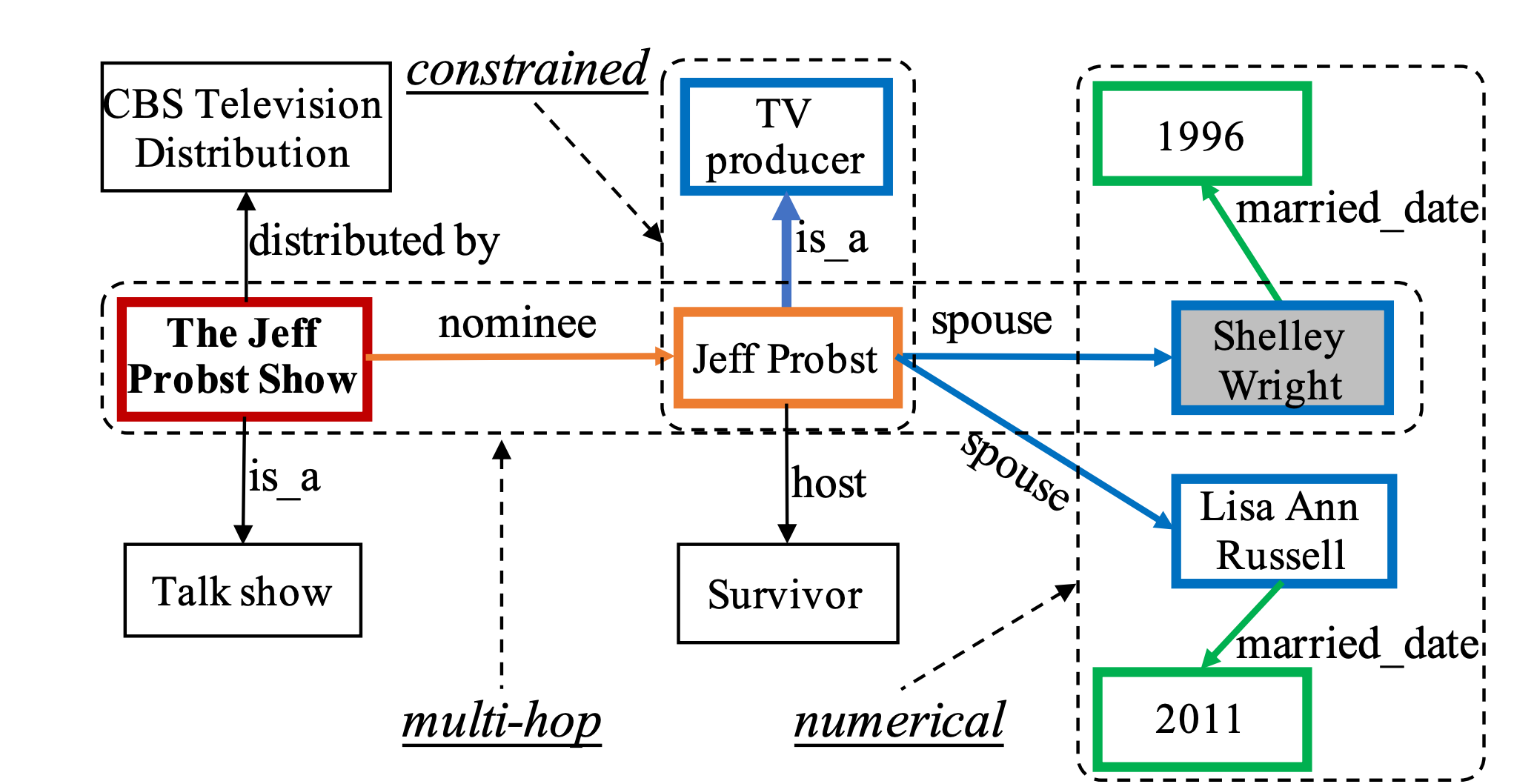
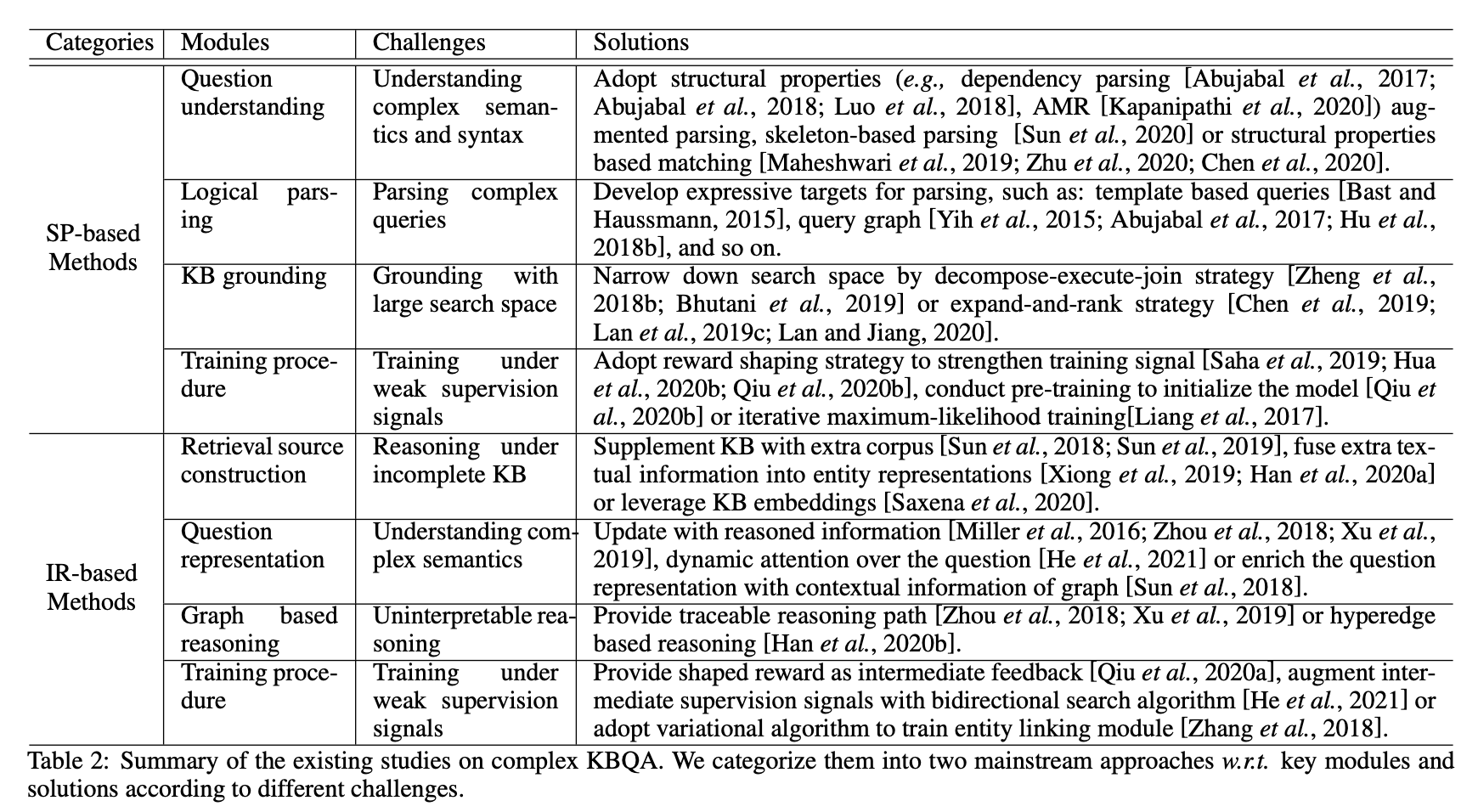
KBQA 的第一步是识别问题中的主体并链接到知识库中的实体,然后根据实体的邻域推导问题答案。这里分为两种方法基于语义解析和基于信息检索的两种方法。语义解析的思想是将自然语言问题表示为可以在知识库中进行查询的符号化的逻辑形式,然后再用逻辑语言进行查询(例如 SQL)。基于信息检索的方法思想是构建一个问题特定的知识图包含了相关的所有信息,然后将所有实体按相关性进行排序。然而,这些方法会面临以下挑战:
- 基于语义解析的方法很难覆盖复杂的查询(多跳推理、约束关系、数值计算等)。类似的,基于信息检索的方法也很难回答复杂的问题,检索的实体范围可能太小,而且解释性差。
- 复杂的实体和关系会使得搜索空间过大(逻辑形式、候选结果等),搜索开销过大。
- 两种方法将问题理解看作重要的步骤,当问题的语法和语义复杂时,模型需要有很强的自然语言理解和生成能力。
- 弱监督问题。问答数据集中往往只存在问题和答案,缺少推理路径,而标注这样的推理路径成本过于高昂。弱监督问题给两种方法都带来了困难。
评估指标上,KBQA 往往是从答案集合上选出置信度最高的,常见的评估指标由 F1、准确率、召回率、Hits@1 等。
主流方法
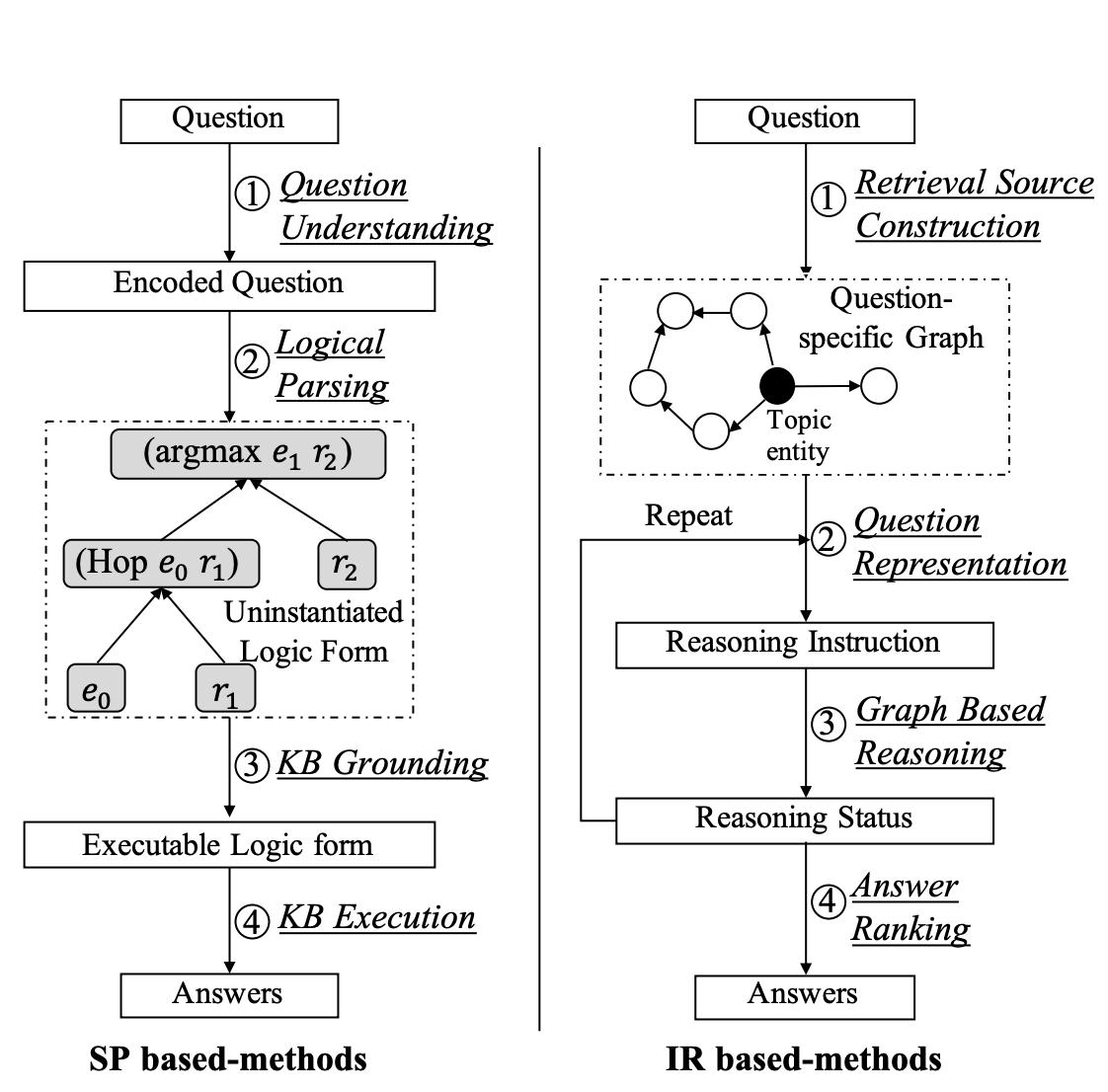
基于语义解析的方法
旨在将自然语言问题解析为逻辑形式,按照以下步骤:
- 问题编码
- 逻辑解析
- 逻辑验证
- 逻辑执行
优点:解释性强
缺点:严重依赖逻辑形式和解析算法的设计,成为性能提升的瓶颈
基于信息检索的方法
旨在根据问题检索候选答案集合并对其进行排序,按照以下步骤:
- 确定中心实体,提取问题特定的部分知识子图
- 问题编码
- 图推理,沿着相邻实体关系进行语义匹配,传播和聚合信息
- 按照置信度进行排序
优点:端到端训练
缺点:解释性差
ODQA
ODQA 问答系统有三种实现方式:先 retrieve 再 read、先 retrieve 再 generate、直接 generate。retrieve 就是根据 Q 从数据库中搜索出一个context,read 是在这个 context 中根据 Q 找 A。generate 是根据 Q 和 context 让机器自己回答,不是在 context 里面找。直接 generate 就是典型的 encoder-decoder 架构。
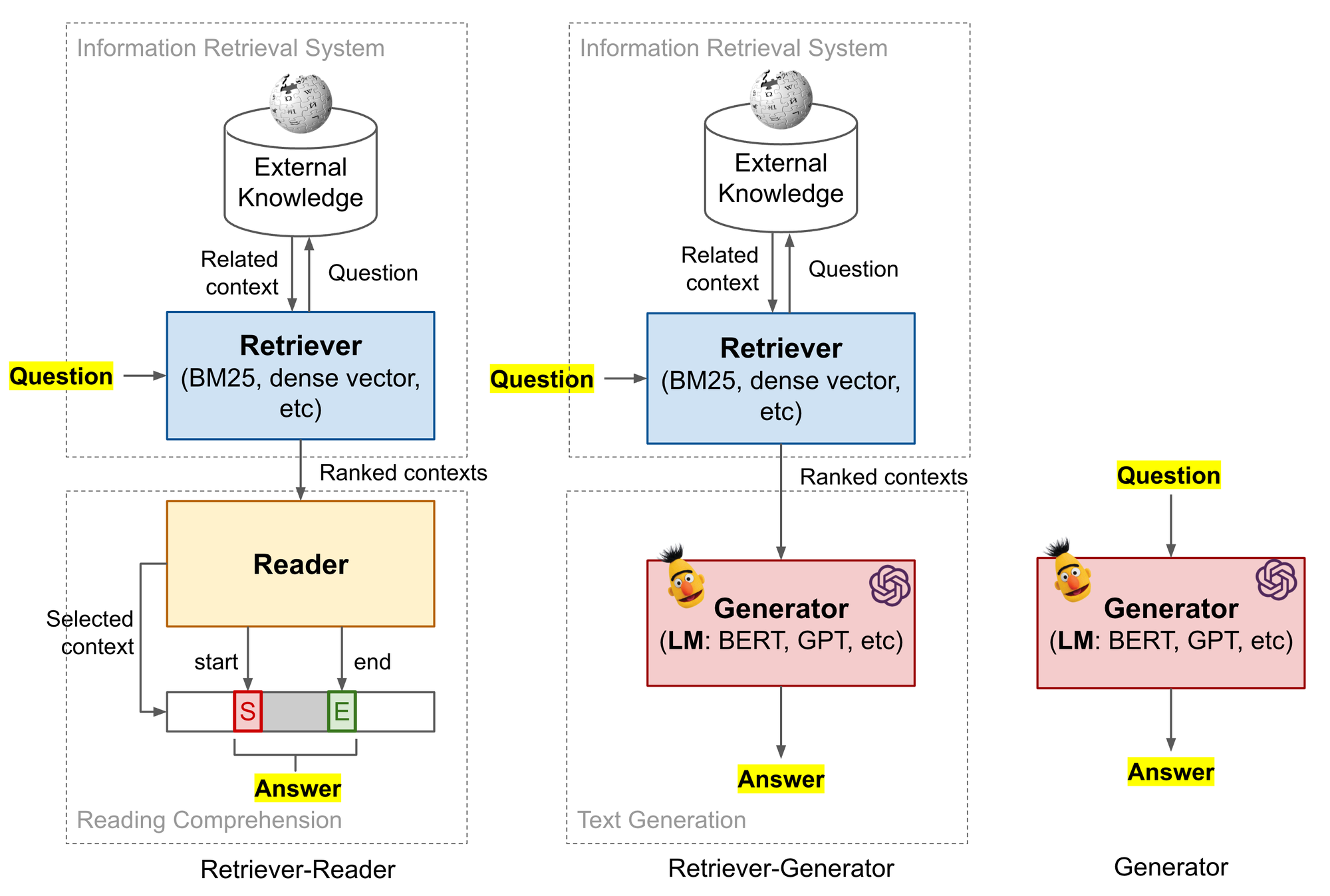
比如 Q :“爱因斯坦为什么赢得了诺贝尔奖?“,A:“光电效应定律。“
“开放领域”部分是指对于任何任意询问的事实问题,都缺乏相关的背景。在上述情况下,该模型仅以问题为输入,但没有提供有关“爱因斯坦为何没有因相对论而获得诺贝尔奖”的文章,其中可能使用了“光电效应定律”一词提到。在同时提供问题和内容的情况下,该任务称为阅读理解(RC)。
基于文档的问答,早在1977年,就由耶鲁大学的“Yale.A.I.Project”提及。2015年开始,学术界开始提出各种大规模数据集(CNN/DM,SQuAD),以推进神经文档问答系统的研究。
Simmons(1964) 对问题和文档的句子进行依存分析树匹配得到答案;
Murax(Kupiec 1993) 用信息检索和浅层语言学处理的方法(譬如,正则表达式)基于在线百科回答问题;
NIST 机构 (1999) TREC QA评测,基于新闻线文本回答问题;
IBM 的 Jeopardy! 系统(DeepQA,2011)使用维基百科和各种知识库、词典乃至新闻内容和书籍作为知识源,用了集成方法,对来自多个数据源对相关内容进行对比来给出回答;
Dr QA (陈丹琦等 2016 年) 首次在信息检索后使用神经阅读理解,将深度学习引进了开放域问答。
传统的 QA 架构分解为很多个模块,尽管复杂,但是对于 Factoid QA(答案是实体类的问答,如 where,what,when,who类问题)效果不错。
经典模型
Stanford Attentive Reader(DrQA)[3]
这是陈丹琦17年提的模型,虽然简单,但是效果不错,据说只要仔细优化结果可以胜过后人提出的不少模型。
对于 Document Retriever,主要作用是从海量数据中快速裁剪搜索空间,所以一般都是用非机器学习的方法。主要是倒排索引+基于词的 tf-idf向量空间检索。据论文的表述,倒排+向量空间检索会比维基百科的内置 ES 检索 api 好,这点感觉挺奇怪的,因为 ES 也是倒排,还加了很多优化,不知是否是因为建索引的数据规模差异导致的,还是维基百科本身的搜索没有怎么优化。
该系统最终采用的方法是文档抽取 bigram,unsigned murmur3 方 法哈希到 2^24 空间中作为词袋,再采用 tf-idf 的向量空间表示,q 和 d 的向量内积作打分,返回 topK 个文档。严格来说不算是倒排表,不过对问题进行文章检索时,是通过稀疏矩阵找到对应文章,所以称为倒排表似乎也可以。
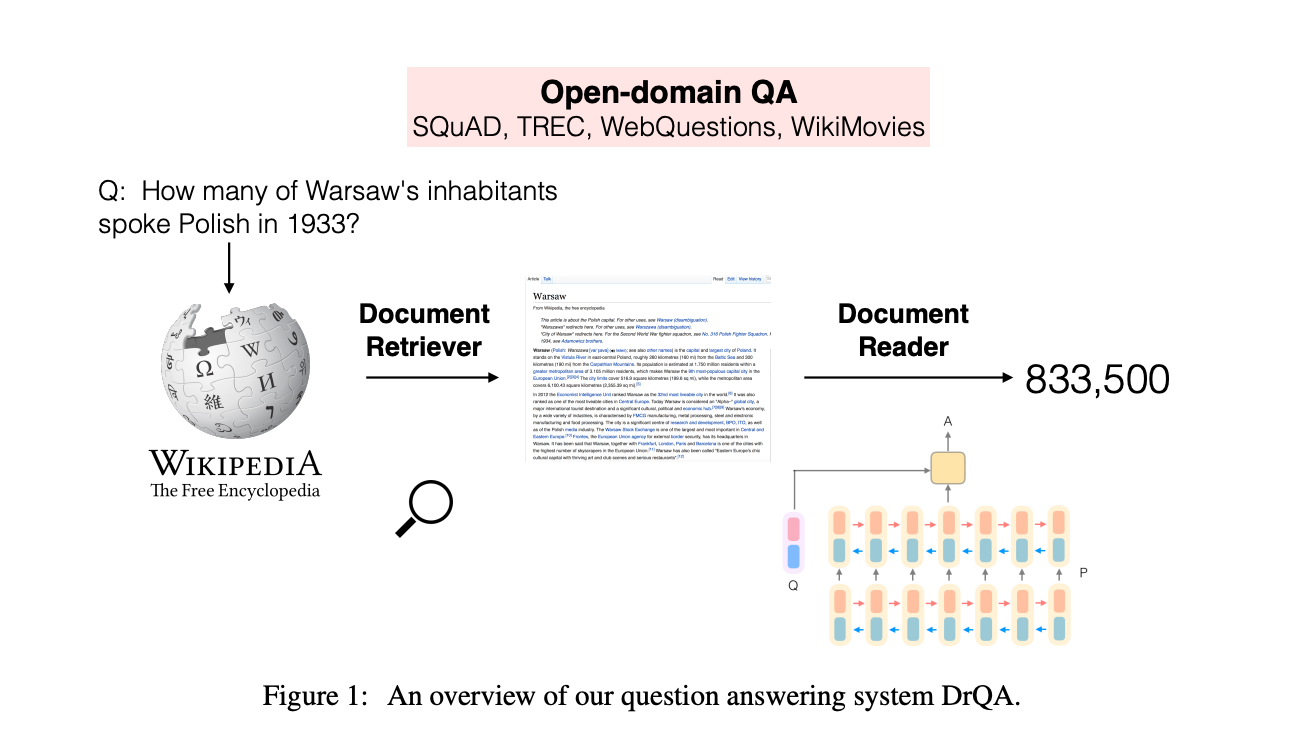
候选文档抽取出来后,我们看下 Document Reader 模块。主要思想是首先对问题用 bi-lstm 编码,取两个方向最终状态拼接起来作为问题的表示,然后再对候选的几个文档段落同样 bi-lstm 计算和 question 表示的attention,分别预测开始位置和结束位置。
BiDAF[4]
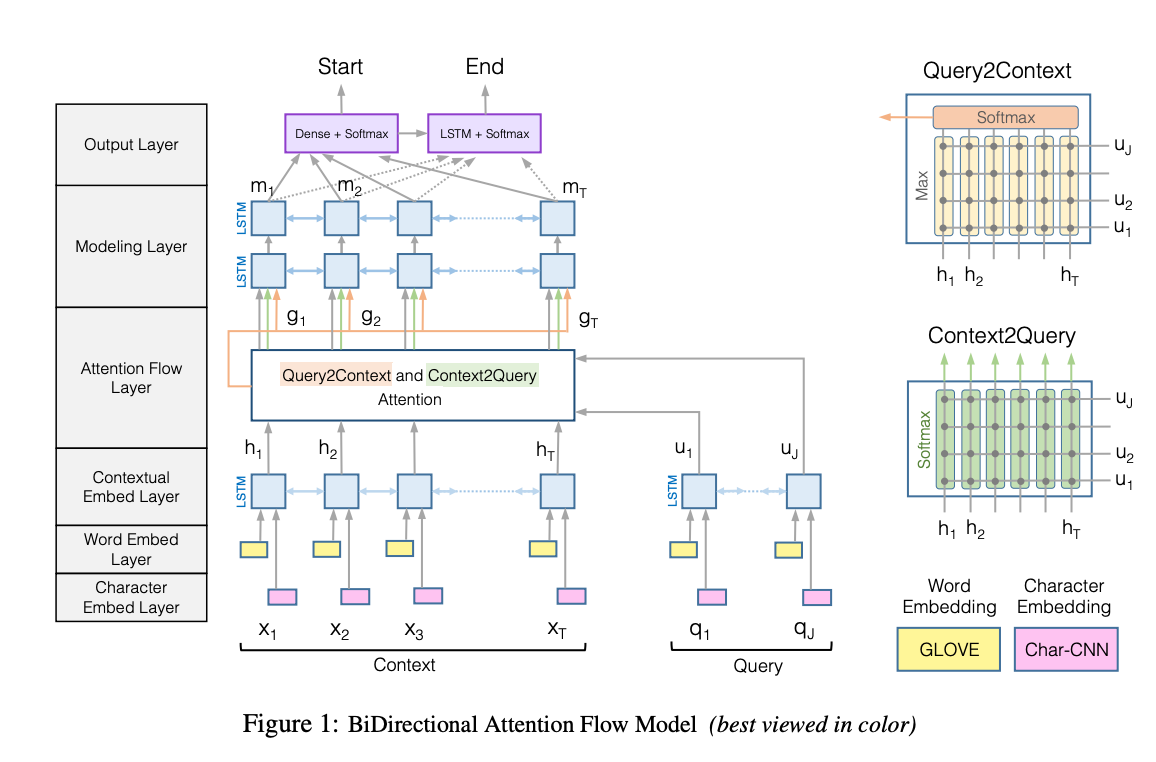
如图所示,该模型的核心是 Query2Context 和 Context2Query 双向attention 流,attention 矩阵是 context 词序列和 question 词序列的相似度矩阵,Context2Query 是对于每一个 context 词,分别计算与 query 各个词的相似度,softmax 归一化后的结果作为权重与 query 词进行加权求和,捕捉 query 中哪个词与当前 context 词最相关;原文中最大的特点就是利用双向注意力流 (Bi-Directional Attention Flow,BiDAF) 得到了一个问题感知的上下文表征。更深层的讲,问题感知的上下文表征是所给段落和问题之间的交互,可以理解为将问题嵌入段落中去,从某种程度上讲相当于一种编码方式。这个很关键,QA 任务中如何建模所给段落与问题的关系,对于后续模型给出答案非常重要。
下面这篇文章有更详细的介绍。
 Lilian Weng
Lilian Weng
参考文献
[1] Reading Wikipedia to Answer Open-Domain Questions, ACL 2017
[2] A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions, IJCAI 2021
[3] Reading Wikipedia to Answer Open-Domain Questions, Danqi Chen∗
作者:Andy.Qin
贡献者:砚安



