从 R-Drop 到 KL 散度
在《R-Drop: Regularized Dropout for Neural Networks》引入了一种一致性的训练策略来规范化 dropout,称为 R-Drop。

论文来自:《R-Drop: Regularized Dropout for Neural Networks》
R-Drop
深度神经网络(DNN)近来已经在各个领域都取得了令人瞩目的成功。在训练这些大规模的 DNN 模型时,正则化(regularization)技术,如 L2 Normalization、Batch Normalization、Dropout 等是不可缺少的模块,以防止模型过拟合(over-fitting),同时提升模型的泛化(generalization)能力。在这其中,Dropout 技术由于只需要简单地在训练过程中丢弃一部分的神经元,而成为了被最广为使用的正则化技术。
Dropout 是一种强大且广泛使用的技术,用于规范深度神经网络的训练。神经网络的训练。虽然有效且表现良好,但 Dropout 引入的随机性可能导致训练和推理之间严重的不一致。
在《R-Drop: Regularized Dropout for Neural Networks》引入了一种一致性的训练策略来规范化 dropout,称为 R-Drop。R-Drop 作用于模型的输出层,弥补了 Dropout 在训练和测试时的不一致性。简单来说就是在每个 mini-batch 中,每个数据样本过两次带有 Dropout 的同一个模型,R-Drop 再使用 KL-divergence 约束两次的输出一致。所以,R-Drop 约束了由于 Dropout 带来的两个随机子模型的输出一致性。
由于深度神经网络非常容易过拟合,因此 Dropout 方法采用了随机丢弃每层的部分神经元,以此来避免在训练过程中的过拟合问题。正是因为每次随机丢弃部分神经元,导致每次丢弃后产生的子模型都不一样,所以 Dropout 的操作一定程度上使得训练后的模型是一种多个子模型的组合约束。基于 Dropout 的这种特殊方式对网络带来的随机性,研究员们提出了 R-Drop 来进一步对(子模型)网络的输出预测进行了正则约束。
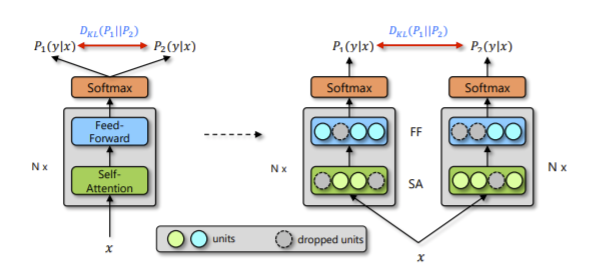
当给定训练数据 \( D={x_i,y_i }_(i=1)^n \) 后,对于每个训练样本 x_i,会经过两次网络的前向传播,从而得到两次输出预测:\( P_1 (y_i|x_i ), P_2 (y_i |x_i) \)。由于 Dropout 每次会随机丢弃部分神经元,因此 \(P_1 \) 和 \(P_2 \) 是经过两个不同的子网络(来源于同一个模型)得到的不同的两个预测概率(如图1所示)。R-Drop 利用这两个预测概率的不同,采用了对称的 Kullback-Leibler (KL) divergence 来对 \(P_1\) 和\( P_2\) 进行约束。然后再加上最大似然损失函数得到新的 loss。

从计算上来说如下,先得到 \(P_1 \) 和 \(P_2 \) 的 KL 散度:
$$ \mathcal{L}_{K L}^{i}=\frac{1}{2}\left(\mathcal{D}_{K L}\left(\mathcal{P}_{1}^{w}\left(y_{i} \mid x_{i}\right) \| \mathcal{P}_{2}^{w}\left(y_{i} \mid x_{i}\right)\right)+\mathcal{D}_{K L}\left(\mathcal{P}_{2}^{w}\left(y_{i} \mid x_{i}\right) \| \mathcal{P}_{1}^{w}\left(y_{i} \mid x_{i}\right)\right)\right) $$
然后通常使用的最大似然损失函数为:
$$L_{N L L}^{i}=-\log P_{1}\left(y_{i} \mid x_{i}\right)-\log P_{2}\left(y_{i} \mid x_{i}\right)$$
最终两个相加再引入一个超参\(a\)来控制即可:
$$L_{i}=L_{N L L}^{i}+\alpha * L_{K L}^{i}$$
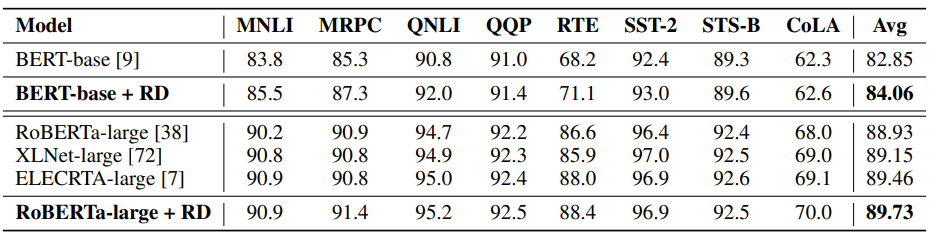
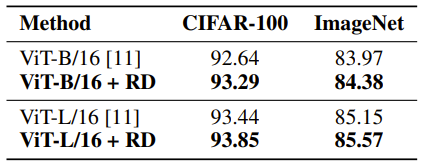
整体来看非常简单,包括代码实现上也很简单,不过在多个任务数据集上都表现出了很好的效果。
import torch.nn.functional as F
# define your task model, which outputs the classifier logits
model = TaskModel()
def compute_kl_loss(self, p, q pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, dim=-1), F.softmax(q, dim=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, dim=-1), F.softmax(p, dim=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
# keep dropout and forward twice
logits = model(x)
logits2 = model(x)
# cross entropy loss for classifier
ce_loss = 0.5 * (cross_entropy_loss(logits, label) + cross_entropy_loss(logits2, label))
kl_loss = compute_kl_loss(logits, logits2)
# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss
KL 散度
我们这里来聊聊 KL 散度,也被称为相对信息熵。在信息论和概率论里面,Kullback-Leibler 散度(简称 KL 散度,KL divergence)是两个概率分布 \(P \) 和 \(Q \) 的一个非对称的度量公式。这个概念是由 Solomon Kullback 和 Richard Leibler 在 1951 年引入的。从概率分布 \(Q \) 到概率分布 \(P \) 的 KL 散度用 \(D_P{KL}(P\|Q) \) 来表示。尽管从直觉上看 KL 散度是一个度量或者是一个距离,但是它却不满足度量或者距离的定义。例如,从 \(Q \) 到 \(P \) 的 KL 散度就不一定等于 \(P \) 从 \(Q \) 到的 KL 散度。
$$D_{K L}(P | Q)=\sum_{i} P(i) \log _{2} \frac {P(i)} {Q(i)}$$
也可以理解成下面这样的写法:
$$ \begin{aligned} &\boldsymbol{D}_{\boldsymbol{K} \boldsymbol{L}}(\boldsymbol{P} \| \boldsymbol{Q}) \\ &:=\sum_{i=1}^{m} p_{i} \cdot\left(f_{Q}\left(\boldsymbol{q}_{i}\right)-f_{P}\left(p_{i}\right)\right) \\ &=\sum_{i=1}^{m} p_{i} \cdot\left(\left(-\log _{2} q_{i}\right)-\left(-\log _{2} p_{i}\right)\right) \\ &=\sum_{i=1}^{m} p_{i} \cdot\left(-\log _{2} q_{i}\right)-\sum_{i=1}^{m} p_{i} \cdot\left(-\log _{2} p_{i}\right) \end{aligned} $$
理论分析
在本小节中,作者分析了 R-Drop 的正则化效应。设 \( h^l(x)∈ R^d \)表示具有输入向量 \(x \)的神经网络第l层的输出,并设 \(ξ^l∈ R^d \)表示一个随机向量,其每个维度从伯努利分布 \(B(p) \)中独立采样:
$$\xi_{i}^{l}= \begin{cases}1, & \text { with probability } p,\\ \ 0, & \text { with probability } 1-p .\end{cases}$$
那么 \( h^l(x) \)上的 Dropout 操作可以用 \( h_{\xi^{l}}^{l}(x)=\frac{1}{p} \xi^{l} \odot h^{l}(x) \)表示,其中 \( \odot \)表示元素的乘积。因此,应用 Dropout 后,参数为 \( w \)的神经网络的输出分布为:
\( \mathcal{P}{\xi}^{w}(y \mid x):=\operatorname{softmax}\left(\text { linear }\left(h{\xi^{L}}^{L}\left(\cdots\left(h_{\xi^{1}}^{1}\left(x_{\xi^{0}}\right)\right)\right)\right)\right)\)
其中\( \xi=\left(\xi^{L}, \cdots, \xi^{0}\right) \),R-Drop 增强训练可表示为解决以下约束优化问题:
$$ \begin{aligned} &\min _{w} \frac{1}{n} \sum_{i=1}^{n} \mathbb{E}_{\xi}\left[-\log \mathcal{P}_{\xi}^{w}\left(y_{i} \mid x_{i}\right)\right] \end{aligned} $$
$$ \begin{aligned} &\text { s.t. } \left.\quad \frac{1}{n} \sum_{i=1}^{n} \mathbb{E}_{\xi^{(1)}, \xi^{(2)}}\left[\mathcal{D}_{K L}\left(\mathcal{P}_{\xi^{(1)}}^{w}\left(y_{i} \mid x_{i}\right) \| \mathcal{P}_{\xi^{(2)}}^{w}\left(y_{i} \mid x_{i}\right)\right)\right)\right] \leq \epsilon \end{aligned} $$
更准确地说,R-Drop 以随机方式约束优化问题,即,它从伯努利分布和一个训练实例 \((x_i,y_i)\) 中采样两个随机向量 \(ξ_{(1)}\) 和 \(ξ_{(1)}\) (对应于两个dropout实例),并根据随机梯度更新参数。
与不使用 Dropout 的损失
\( \mathcal{L}=\frac{1}{n} \sum_{i=1}^{n}-\log \mathcal{P}^{w}\left(y_{i} \mid x_{i}\right) \)相比,优化损失 \( L_{NLL} \) 通过控制模型 \(\mathcal{P}_{\xi}^{w}(\cdot)\) 的雅可比矩阵来限制模型的复杂性。
实际上,约束神经网络任意两个子结构的 KL 散度会对神经网络参数的自由度产生约束。因此,约束优化的问题转而寻求一个模型,该模型可以在参数自由度最小的情况下最小化损失 \(L_{NLL}\),从而避免过拟合并提高泛化能力。
总结
Dropout 会随机使一些元素为0,通过这个子模型(当模型使用 Dropout 时,未遮蔽的神经元组成的模型)训练,最终的结果就是让大模型中有多种解决问题的子模型,从而提升模型的泛化能力。将同一个样本直接送入一个带有 Dropout 的模型两次计算 crossentry loss 相当于额外的多了一条数据,做了次数据增强。
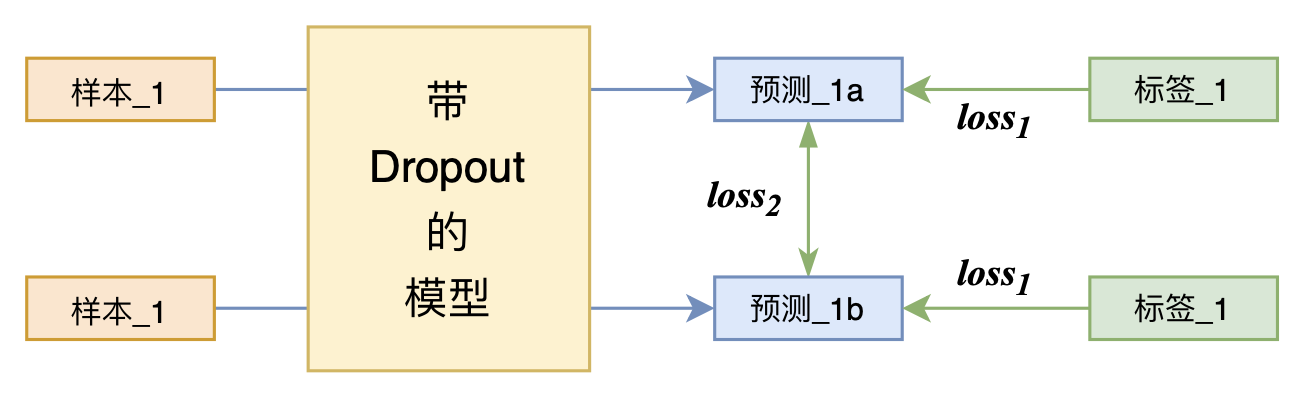
R-drop 在这个基础上又增加了一个强干预项,就是不仅预测结果要一样,还要保证这两句话的 KL 散度较低,这就保证了同一个句子在不同的子模型下的输出尽可能一致。