OpenAGI: When LLM Meets Domain Experts 浅析
这篇论文文介绍了一种开放式人工智能(AGI)研究平台 OpenAGI,旨在用自然语言查询作为输入,通过大型语言模型(LLMs)选择、合成和执行外部模型,解决复杂的多步任务。

今天带来的论文是来自Rutgers University 大学的:《OpenAGI: When LLM Meets Domain Experts》。这篇论文文介绍了一种开放式人工智能(AGI)研究平台 OpenAGI,旨在用自然语言查询作为输入,通过大型语言模型(LLMs)选择、合成和执行外部模型,解决复杂的多步任务。本文的研究成果是一种新型的 AGI 研究平台,通过 LLMs 和各种扩展模型来处理复杂任务。该平台提供了一种自我改进的机制,以从任务反馈中进行强化学习,从而提高 LLM 的任务解决能力,形成自我完善的 AI 反馈循环。这种 LMMs 操作各种专家模型来解决复杂任务的方法是实现 AGI 的一种有前途的途径。然而,该方法仍然存在一些问题,例如如何平衡领域专家模型的准确性和深度学习模型的表现力,如何更有效地获取任务反馈等。这些问题需要进一步研究和探讨,以实现更好的 AGI 能力。
背景
在最近的 LLM 中像 GPT-3 brown2020language、 LLaMA touvron2023llama 和 Flan-T5 chung2022scaling 都表现出对自然语言的深刻理解以及生成连贯和上下文相关响应的能力。这为它们在涉及多模态数据的复杂任务中的应用开辟了新的可能性,例如图像和文本处理,以及特定领域知识的整合。在这个过程中,LLM 发挥了至关重要的作用,因为它们可以理解和生成自然语言,这有助于AI更好地理解和处理各种问题。 通过整合来自不同领域的知识和技能,开放领域模型合成(OMS)有可能推动通用人工智能(AGI)的发展,使 AI 能够解决各种问题和任务。
但目前存在两个问题:
- 可扩展性,这些模型采用了固定的专家模型数量,如果要扩展功能比较难。
- 需要非线性规划,目前的大部分研究仅限于用线性任务规划解决方案来解决任务,这意味着每个子任务必须在下一个子任务开始之前完成。而模型的线性规划可能不足以解决复杂的任务,此外,许多任务涉及多个多模态输入。
- 量化评估:难以评估的这种能力的 LLM 采用的策略是最佳的。

为了解决上述的问题,OpenAGI 包含各种特定领域的专家模型和复杂的多个步骤的任务,支持单个或多个模态的输入。基于 HuggingFace 的相关库和 GitHub 上的数据集精心筛选后进行对齐。然后利用一些数据增强技术来增强这些数据集用来构建复杂的多步骤任务。
- 选择自然语言的任务描述与任务相关的数据集;
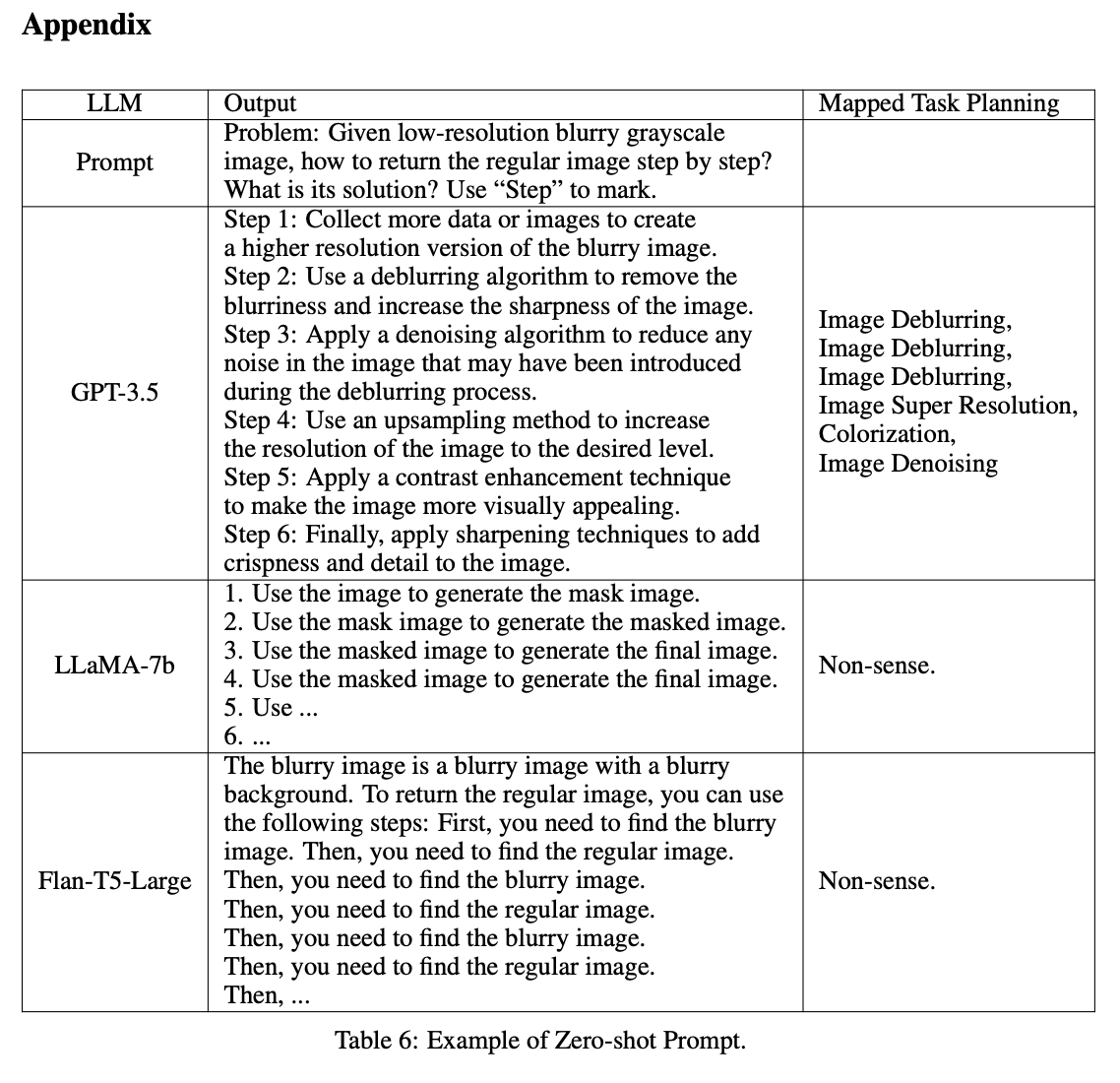
- 将任务描述作为输入输入到 LLM 中,以生成解决方案,这可能需要将解决方案映射到功能模型名称,或使用约束生成直接生成模型名称;(如上图第二列输出了好几项任务)
- 根据第二步生成的任务列表选择相应的模型并执行;
- 可通过比较输出和真实标签来评估 LLM 的任务解决能力。
如上方的任务是要求将低分辨率、有噪声、模糊的灰度图像转为正常图片。
但 OpenAGI 也有以下问题:
- Out-of-Distribution (OOD) Generalization. 由于对训练数据分布的强烈依赖,特定领域的专家模型可能表现出有限的泛化能力。如下图所示:

- Optimal Task Planning. 组合不同模型以生成解决方案的方法有多种,这使得确定最佳方法变得困难。 此外,对于一个给定的任务,可能存在多个有效的解决方案,但每个解决方案的质量可能会有很大差异。如下图所示,以不同的顺序执行相同的四个模型可能会导致明显不同的结果。第二种方法的结果(即,图中的第二行)与第一种方法相比表现出明显更多的噪声和颜色不一致性,因此顺序是至关重要的 LLM 识别和实施最佳的任务计划的关键。

- Nonlinear Task Structures. 在模型执行期间,模型可能需要多个输入,并且每个输入都需要由先决条件模型生成,从而能解决方案的非线性(树)结构。 在这种情况下,采用非线性任务规划可以更有效地整合不同的输入,更有效地并行处理模型,以实现预期的结果。然而,将这种非线性任务规划能力纳入 LLM 提出了超出 LLM 现有任务解决能力的独特挑战。
主要工作
给定一组基于自然语言的任务描述 T 和一组数据集 D,其中每个元素 Dt 表示特定任务t 的对应数据集,以及 D 上的功能模型的集合(表示为 M)及其对应名称集 N,给定 LLM 的目标(表示为 L)是将特定任务描述 t 作为输入并产生多步解决方案 s。该解决方案可以基于模型名称集被映射到功能模型的布置(线性地或非线性地),最终在任务相关的数据集上工作以完成任务。因此,只要提供 T、D、M 和 N,就可以采用从任何学习模式导出的任何 LLM 来评估该上下文中的 LLM 的规划能力。
在 OpenAGI 平台上定义了以下几种类型的领域模型:
- 语言相关模型,用于解决情感分析、文本分类、文本摘要等问题。
- 视觉相关模型,用于解决图像分类、对象检测、超分辨率等问题。
- 视觉语言模型:用于解决视频问答、基于图像问答、文本生成图像等问题。
在选择了合适的模型之后,选择数据集就变成了一个更简单的过程,前提是我们要确保数据集和模型的训练集之间的正确对齐。选用的数据集有 ImageNet-1K、Common Objects in Context (COCO)、CNN/Daily Mail、Stanford Sentiment Treebank (SST2)、TextVQA、Stanford Question Answering Dataset (SQuAD)。
在确定数据集后,我们的下一个目标是从各种角度对其进行增强,以构建复杂的多步骤任务。例如,我们可以引入噪声并降低 ImageNet-1 K 中图像的分辨率,以创建新的数据集,这些数据集可能需要“图像去噪”和“图像超分辨率”进行初始恢复,然后再进行分类。用了高斯模糊、灰度、降低分辨率、翻译、 Mask 一些词语等方案。
根据上方的模型选择,我们根据输入和输出模式对它们进行了分类。我们根据输入和输出模式将它们分类如下:1)图像输入,图像输出;2)图像输入,文本输出;3)文本输入,图像输出;4)文本输入,文本输出;5)图像-文本对输入,文本输出;6)文本-文本对输入,文本输出。
我们采用上面讨论的数据增强技术来增强原始数据集。具体地,对于具有图像输入的任务,我们可以从图像增强方法集合{高斯模糊、高斯噪声、灰度、低分辨率}中选择一种或多种技术来生成成分增强的图像输入,这需要多步图像恢复过程来进行恢复。类似地,对于具有文本输入或输出的任务,我们从{翻译,单词掩码}中选择一个或多个以生成合成增强的文本输入或输出。此外,视觉问答(VQA)和问答(QA)是具有多个多模型输入的任务,导致无法用线性任务规划解决方案解决的自然任务。最后,我们将这两个方面结合起来,构建复杂的多步骤任务。 总的来说,我们生成了总共 185 个复杂的多步骤任务,其中117个任务具有线性任务结构,其余 68 个任务具有非线性任务结构。
在上方表格中可以找到一些任务样本,以及它们相应的输入和输出数据样本。
鉴于 OpenAGI 包含多种具有多模态数据的域任务,我们根据域任务以及输入和输出类型对其进行分类。然后,我们使用以下三个指标评估他们的表现:
- CLIP Score,用于评估生成的图像标题与图像的实际内容之间的相关性。
- Bert Score,使用来自预训练 BERT 模型的上下文嵌入,通过余弦相似度比较候选句子和参考句子中的单词。此外,BERT Score 还计算精确度、召回率和 F1 度量,使其成为评估各种语言生成任务的有价值的工具。在这项工作中,我们使用 F1。
- Vit Score,设计用于评估两个图像之间的视觉相似性。通过计算使用视觉变换器生成的各自嵌入的余弦相似度。

我们采用的 CLIP 分数仅用于基于文本到图像生成的任务,BERT 分数被用来评估任务的文本输出,和 ViT 分数被应用于测量图像相似性的其余任务的图像输出。我们还将 BERT 和 CLIP 评分标准化。
针对上面提到的「分布外 (OOD) 泛化」和「最佳任务规划」两个问题,「作者引入了一种称为任务反馈强化学习 (RLTF) 的机制」。该方法利用任务解决结果作为反馈来提高 LLM 的任务解决能力。 因此,RLTF 机制有效地改进了 LLM 的规划策略,从而形成了一个增强的、更具适应性的系统。 事实上,在面对现实世界的任务时,仅依靠输入文本进行学习是不够的。 另一方面,任务反馈提供了额外的信息,可以引导 LLM 的学习轨迹朝着改进和高效的解决方案发展。

针对上面提到第三个非线性规划问题,作者提出了非线性任务规划的方案。
为了生成自然语言任务描述的解决方案,我们要求 LLM 生成一个由模型名称序列组成的可操作解决方案。对于只需要一个输入的任务,模型只需要生成一个可操作的模型序列。对于需要多个输入的任务,例如视觉问答,LLM 需要多个步骤来完成任务,其中每个步骤是一系列模型或几个模型序列的并行。为此,LLM必须满足三个条件:1)仅生成模型名称而没有不相关的标记,2)生成有效的模型序列,以及3)在必要时为不同的输入生成并行的模型序列。
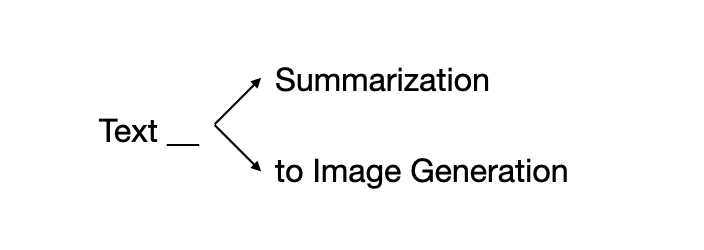
条件一:对于 LLM 仅生成模型名称,而不是调整模型来教导它哪些名称可用,我们采用 beam search de2020autoregressive,它只允许在每个解码步骤中从 M 生成令牌。更具体地说,我们将约束定义为前缀 trie,使得每个模型名称都是从根到某个叶节点的路径。对于树中的每个节点 t,其子节点指示从根到 t 遍历 trie所定义的前缀的所有允许的延续。因此,在每个解码步骤中,下一个标记只能从基于所生成的标记允许的所有可能的延续中选择,或者只能从所有可能的下一个模型名称的第一个标记中选择。例如,如果基于模型名称的集合已经生成了“文本”,则下一个令牌只能是由于“文本摘要”模型而导致的“摘要”或由于“文本生成”模型而导致的“生成”,如下图所示。
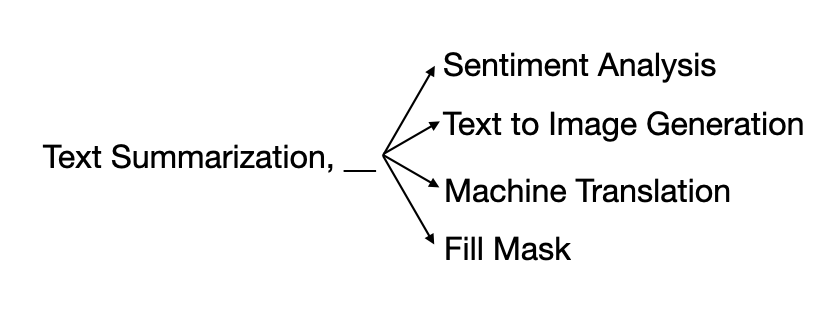
条件二:为了使 LLM 生成有效的模型序列,连续的模型应该具有匹配的输入和输出模态。如果一个模型的输出模态是文本,那么下一个模型只能是将文本作为输入的模型。这也通过约束波束搜索来实现,使得当完成生成一个模型时,约束函数将确定该模型的输出模态,并找出 M 中所有可能的下一个模型,排除已经生成的模型。它将基于输出模态为所有这些模型名称动态地构造一个新的 trie。例如,如果第一个生成的模型名称是“文本摘要”,则下一个可能的模型可以是“情感分析”、“文本生成”等。如下图所示。
条件三:语言模型中的自回归解码通常不适合于生成并行有效序列。在这项工作中,我们使用波束搜索进行半自回归生成。Beam search 最初被提出,使得生成多个假设以彼此竞争,以便获得最高得分的输出。相反,我们利用 Beam search 作为有效的半自回归解码方法 rubin2020smbop,使得对于波束搜索中的每个解码步骤,不同的假设被视为不同输入的并行有效解,而不是竞争假设。如果任务需要多个输入,例如文本和图像,则在生成时间中,以文本作为输入的模型和以图像作为输入的模型几乎同样可能被生成。由于基于约束生成,每个波束最终是一个有效的模型序列,因此,将并行生成具有不同输入类型的多个有效序列。
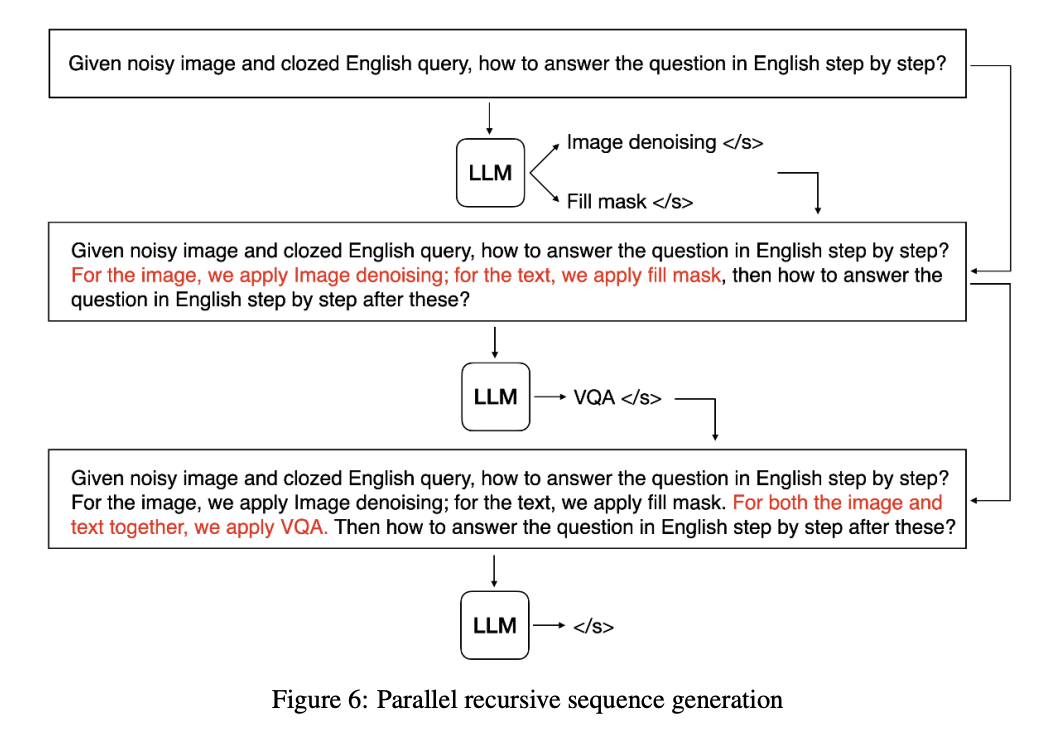
如果一个任务需要并行处理多个输入,例如文本和图像,那么在生成时间内,将并行生成并执行以文本为输入的可操作解决方案和以图像为输入的另一个解决方案。在进行并行处理时,需要建立多输入模型和后续模型。我们将生成的序列与自然语言任务描述连接起来,以生成一个新的提示符来提示后续的模型。这个过程可以递归完成,直到在没有任何模型的情况下生成句尾标记,如图下图所示:
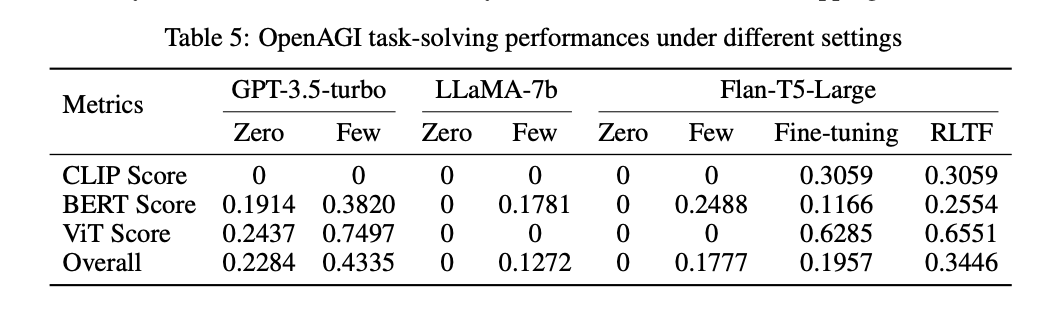
为了便于对结果进行全面分析,我们在表格中提供了 Zero 和 Few。 很明显,在 Zero 中,大多数 LLM 都很难生成有效的任务规划,更不用说最佳解决方案了。特别是,GPT-3.5 倾向于生成重复的内容,这些内容随后映射到相同的模型名称。与此同时,LLaMA-7 b 和 Flan-T5-Large 由于受到其 Zero 能力的限制,未能制定合理的计划。
表格中分别是 Zero 没有学习过只是简单的讲任务描述给模型要求给出结果,Few 提供了一组高质量的示例来辅助模型理解任务应该输出什么样的答案,Fine-tuning 是将手动标注的数据进行了微调训练,同样也使用了上方的三个条件。RLTF 就是上方的方法。整体性能计算为 CLIP、BERT 和 ViT 得分的加权平均值。

结论
个人认为这是一个比较简单且有效的方案,虽然一个统一所有模态和下游任务的超大模型是未来的大势,但是在目前为止还是比较难实现的,所以我们需要利用 LLM 的学习、归纳和推理能力将一个任务拆解为多个任务,然后利用不同领域的更擅长的模型去解决问题。在这样的设计中 LLM 就有点像是一个指挥官,制定计划并要求执行。
将复杂任务拆解为多个可执行的任务是一个比较好的方向,AutoGPT 的爆火其实就验证了这件事的可能性,有点像 OKR 对齐。将复杂的、模糊的任务不断拆解成更简单的、更具体的任务,然后利用其它方式执行、搜索、查询、推理等等。比如 “腾讯 2024 年预计年净利润为多少?”就需要拆解为一些更具体的任务和工作。