如何快速排查故障
故障排查是每个工程师都要掌握的一项关键技能,但是有些人这方面特别强,有些人这方面却特别弱。而让强的人去讲解他们是如何排查故障也特别难,他们是近乎于本能的发掘故障的原因。

故障排查是每个工程师都要掌握的一项关键技能,但是有些人这方面特别强,有些人这方面却特别弱。而让强的人去讲解他们是如何排查故障也特别难,他们是近乎于本能的发掘故障的原因。
随着系统的复杂度不断的提升、业务的发展加速,排查故障的难度将来越来越大。复杂的系统本身都是高风险系统,而这些复杂的系统爆发事故的频度高又会催生各式各样的防范措施,这些防范措施又会不断的催生更多复杂的系统。
比如说一个电商网站,那么为了保障电商网站的性能和可用性,会需要建设 API 监控、网页性能监控、支付网关监控等系统。
在复杂的业务系统下,重大灾难事故往往都是由多起无足轻重的轻微故障共同导致的系统性的意外事故。这些轻微故障中的每一起都是事故的诱因,但只有当它们叠加在一起时,才会酿成事故(类似多米诺骨牌效应)。换言之,故障的发生概率比重大系统事故的发生概率要高得多。
在一个相互联系的系统中,一个很小的初始能量就可能产生一系列的连锁反应,人们把这种现象称为“多米诺骨牌效应”或“多米诺效应”。
除非真的发生事故,否则我们也很难看出这些故障如何会诱发事故。不断演变的技术和工作机构,再加上人们为了排除故障而付出的种种努力,使得故障也不断地发生变化。
工程师一边工作生产代码,一边防范事故的发生。外界很少有人能够认识到这一角色的二重性。系统正常运转时,主要负责的工程师是生产角色;事故发生后,工程师则换成了故障防范角色。实际上,系统操作人员一直长期且持续地分饰二角。只要持续生产、迭代就会有变化,只要有变化就会出现故障。
那么快速排查故障、提前定位问题就成为复杂系统必须要具备的一项技能,甚至要变成本能。
想要快速排查故障需要两个硬性条件:
- 知道通用的故障的原因(与特定系统、业务无关的,如 DNS 解析错误等等)及解决方式
- 对发生故障的系统足够了解。
这两个硬性条件往往是很多人无法快速排查问题的主要原因。
一个基本的故障排查过程可以被定义为是反复采用“假设-排除”的手段的过程,即针对某个系统的观察结果及故障的现象和对这个系统的运行机制的认知不断提出可能导致问题的假设,然后再针对这些问题进行测试和排查。
有时候再定位问题和排查环节上,常常会因为不熟悉发生故障的系统的原理、运行机制导致出现下面这些浪费时间的情况:
- 过分着重错误的故障现象
- 因为不了解运行机制,无法正确的修改配置、环境,导致不能安全的验证假设。
- 过早的将问题归于不可能的因素。
- 试图解决一些由根本问题引发的其它问题。
我们前面有讲到,在复杂的系统下,发生严重故障时很容易发生多米诺骨牌效应。所以在排查问题时一定要注意相关性≠因果关系 。如工程师发现有个 API 很慢,却忽视了这个 API 可能是因为背后调用的其它服务或者是数据库很慢,而如果是数据库的话可能是因为它的没有设置合理的索引或是没有很好的缓存机制导致很慢等情况。在前面这个场景下 API 很慢、数据库查询很慢等等都只是现象,本质上的原因可能是因为没有设置合理的索引或是没有很好的缓存机制。
在定位问题时的推理过程中,我们要避免过于关注故障的现象,要尽可能找到故障的本质原因。近乎本能的将我知道的和我不知道的情报区分开来。
一般我们在收到错误报告时,我们需要尽快的弄明白是什么问题,以及确定问题的严程度。如果问题非常严重的话,应该先尽可能的让系统进行恢复,比如将流量转移到正常的节点、回滚等等,避免由单一故障引发多米诺骨牌效应是第一优先级。
在确保了你有时间去检查问题后,再开始检查问题。我们可以在看到故障的现象后通过查阅日志、查看系统监控指标等方式来帮助定位问题。
有时候在多层系统下,有些故障它并不是由于单一系统引擎的,可能是由于其它系统引起的。我们可以使用分治法,就是通过这个故障系统开始一端端的排查,直至系统底层。
1、归并排序首先把原问题拆分成2个规模更小的子问题。
2、递归地求解子问题,当子问题规模足够小时,可以一下子解决它。在这个例子中就是,当数组中的元素只有1个时,自然就有序了。
3、最后,把子问题的解(已排好序的子数组)合并成原问题的解。
当然你也可以使用二分法,将系统一分为二,上至下,下至上的进行检查。
二分法(Bisection method) 即一分为二的方法. 设[a,b]为R的闭区间. 逐次二分法就是造出如下的区间序列([an,bn]):a0=a,b0=b,且对任一自然数n,[an+1,bn+1]或者等于[an,cn],或者等于[cn,bn],其中cn表示[an,bn]的中点。
当你有个可能性问题清单的时候,如果你不确定应该从哪个问题开始排除时,根据奥卡姆剃刀原则,当你的问题清单都能解释观测到的事实,那么你应该使用简单的那个,直到发现更多的证据。
奥卡姆剃刀是由14世纪英格兰圣方济各会修士威廉提出来的一个原理。他出生在英格兰萨里郡的奥卡姆镇。威廉曾在巴黎大学和牛津大学学习,知识渊博,能言善辩,被人称为“驳不倒的博士”。
威廉曾写下了大量的著作,但都影响不大。但他却提出了这样的一个原理:如无必要,勿增实体。其含义是:只承认一个个确实存在的东西,凡干扰这一具体存在的空洞的普遍性概念都是无用的累赘和废话,应当一律取消。他使用这个原理证明了许多结论,包括“通过思辨不能得出上帝存在的结论”。这使他不受罗马教皇的欢迎。不久,他被教皇作为异教徒关进了监狱,为的是不使他的思想得到传播。在狱中过了四五年,他找到机会逃了出来,并投靠了教皇的死敌--巴伐利亚的王爷。他对王爷说:“你用剑来保卫我,我用笔来保卫你。”正是这次成功的越狱,成就了威廉的威名。他的格言“如无必要,勿增实体”也得到了广泛的传播。这一似乎偏激独断的思维方式,后来被人们称为“奥卡姆剃刀”。
我们来看一个阿里技术发表的一个排查案例。
某日,做产品 X 的开发接到客户公司电话,说是对账出了 1 分钱的差错,无法处理。本着“客户第一”的宗旨,开发立马上线查看情况。查完发现,按照产品X当日的年化收益率,正常情况下用户在转入 57 元后一共收益 3 分钱,合计是 57.03 元。但是该客户当日却有一笔消费 57.04 元,导致客户公司系统对多出的 1 分钱处理不了。再进一步分析,发现用户收益结转时多了 1 分钱的收益,并且已消费……
也就是说,本来用户只有3分钱收益,结果多发了1分钱给他,也就给公司造成1分钱的损失!用户在产品X里当天收益本应该是 0.03 元,怎么会变成 0.04 元呢?多出的 1 分钱收益从哪里来的呢?
确定问题和严重程度
带着上面的一系列疑问,开发人员首先排查了产品 X 收益的数据库记录。通过查询数据库发现,该用户收益结转在同一天内存在 2 笔交易记录。交易记录1创建时间为 8:00:23,记录2创建时间为 8:00:29,交易记录 1 和 2 的最后修改时间均为 8:00:29,如图所示。
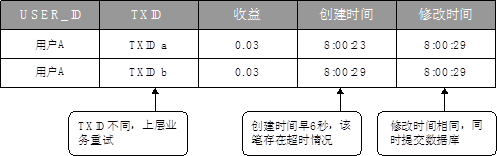
正常情况下产品X收益每天只会结转一次,而这个用户当日有两笔收益结转记录。开发人员怀疑,很可能是出现了并发问题。
查看日志
继续跟踪第一笔“TXID a”的记录,开发确认线上日志存在超时情况,失败原因是数据库链接数已满,线程等待提交。
使用分治法一层层的排查
分布式锁超时时间是 5s,第一笔记录从创建到修改提交经历了 6s,由此可见是在分布式锁失效之后,获得了数据库链接,进行提交成功。
有了以上三个排查思路后,我们可以开始逆推整个过程。
正常情况下产品X收益每天只会结转一次,而这个用户当日有两笔收益结转记录。开发人员怀疑,很可能是出现了并发问题。
继续跟踪第一笔“TXID a”的记录,开发确认线上日志存在超时情况,失败原因是数据库链接数已满,线程等待提交。
分布式锁超时时间是 5s,第一笔记录从创建到修改提交经历了 6s,由此可见是在分布式锁失效之后,获得了数据库链接,进行提交成功。
有了以上三个排查思路后,我们可以开始逆推整个过程。
根据数据库记录逆推当时的运行情况,如图所示。

(1)由于数据库连接数被占满,流水1创建的事务处于等待提交状态。
(2)系统A发现交易失败,重试次数不满8次的,立即发起重试,触发生成流水2的请求。
(3)5s 以内数据均被分布式锁拦截,无法提交。
(4)经过 5s 后,系统B的分布式锁失效,此时事务仍在等待未提交。
(5)6s 时,流水 2 成功越过数据库查询幂等校验发起事务,此时流水 1 拿到数据库连接,流水 1 和 2 两个事务同时提交。
(6)由于数据库未做唯一索引,且支付受理模块打穿下层幂等原则,生成 2 个TXID,导致两事务同时提交成功。
(7)收益结转重复记账,用户多了一笔收入。
相关性≠因果
完成了整个问题的过程逆推后,开发人员进一步分析,发现问题真正的原因还是在系统设计上。如图所示,系统A的事务允许一定时间的等待,而上层业务的重试时间又比这个等待的时间要短。这就存在一个问题:系统A的事务还在等待中,业务就又发起了重试。如果是在这个应用场景下(可能业务上对重试要求更高一些),那么对幂等控制的要求就更高了。而仅仅通过一个分布式锁来控制,如果分布式锁的超时时间设置的比事务允许等待的时间短,那么在锁失效之后就一定会同时提交两笔请求。

继续对整个过程抽象化,开发人员得出一个结论:分布式锁在以下条件同时满足的情况下并发控制会被打穿。
(1)上层业务系统层面有重试机制。
(2)业务请求存在一定时间之后提交成功的情况,例如本例中第一次请求在事务等待 6s 后获得了数据库链接,提交数据库成功。
(3)下游系统缺乏其他有效的幂等控制手段。
提出修复方案并进行测试
了解了问题的来龙去脉后,接下来要怎么解决这类问题呢?我们想了以下几个方案。
(1)调整 B 系统上的 tr 和分布式锁超时时间,tr 超时调整为 10s,分布式锁超时调整为 30s。
(2)防止做收益结转产生并发控制幂等,调整了收益结转流水号的生成规则:前 8 位取 X 收益结转传入的交易号的前 8 位,第 10 位系统版本设置为“9”,最后 8 位 seq 取交易号的最后 8 位,降低问题出现几率。
方案一:调整超时时间
调整超时时间后,业务重试时间与分布式锁有效时间的分布时间轴如图所示,即在事务允许等待后提交成功的时间之外,再进行重试,另外分布式锁在整个阶段均有效,防止提交。

方案二:增加幂等控制(推荐)
如图所示,单纯靠分布式锁不是控制并发幂等的方式,最稳妥的方式还是在提交记录的时候通过数据库严格控制幂等。确保不论如何设置超时时间,都不会出现幂等控制的问题。
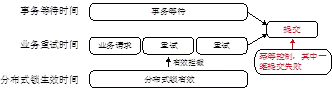
最后两个方案经过验证都是有效的。在这个案例中,从问题分析定位,到整个逻辑的梳理清洗,其中涉及了三个时间轴的相互作用,再加上事务、分布式锁、重试等,整个问题发生的逻辑还是比较复杂的。因此,在系统并发幂等控制设计中,单纯的分布式锁并不具备严格控制并发幂等的作用。
建议在企业中,公布故障排查过程、建立故障的知识库以及让所有的新入职的人接触故障记录的知识库是非常有利于新人快速成长的。